PostgreSQL
یکی از تفاوت های کاملا بارز بین اَپلیکیشنی که صرفا جهت دستگرمی روش کار میکنیم با اَپلیکیشنی که میخواهیم به بازار ارائه بدیم، دیتابیس هستش. جنگو بمنظور توسعه محلی با خودش دیتابیس SQLite رو بعنوان دیتابیس پیشفرض به همراه داره که علتش کوچک، سریع و مبتنی بر فایل بودن این دیتابیس هستش که استفاده ازش رو ساده میکنه و نیازی به پیکربندی اضافی نیست.
اگرچه این راحت بودن بهای خودش رو هم داره. بطور کلی SQLite دیتابیس مناسبی برای وب سایتهای حرفه ای نیست. پس با وجود اینکه برای پیاده سازی اولیه ایده های خودمون استفاده از این دیتابیس موردی نداره، اما خیلی نادره که از این دیتابیس به عنوان دیتابیس یک پروژه حرفه ای استفاده بشه.
جنگو بصورت توکار از پنج دیتابیس پشتیبانی میکنه: PostgreSQL، MariaDB، MySQL، Oracle و SQLite. ما قراره توی این فصل از دوره از PostgreSQL استفاده کنیم که محبوبترین گزینه در بین اجتماع توسعه دهندگان جنگو هستش؛ گر چه زیبایی ORM(Object-Relational-Mapper) جنگو در این هستش که حتی اگر ما میخواستیم از MySQL، MariaDB یا Oracle استفاده کنیم، کد جنگویی که نوشتیم تقریبا یکسان میبود. ORM جنگو بطور اتوماتیک به کار ترجمه کد پایتون به پیکربندی SQL مخصوص به هر دیتابیس رسیدگی میکنه که به نوبه خودش قابلیت فوق العاده ایه!
چالشِ استفاده از دیتابیس هایی که مبتنی بر فایل نیستند اینه که باید بصورت محلی(Local) نصب و اجرا بشن تا بتونن به درستی تقلیدی از یک محیط توسعه آماده به تولید به شما ارائه بدن که ما هم همینو میخواهیم! با وجود اینکه جنگو خودش بجای ما به جزئیات تعویض کردن دیتابیس ها رسیدگی میکنه ولی باز هم یک سری باگ های کوچک و غیرقابل اجتنابی وجود دارند که اغلب مواقعی رخ میدن که شما برای توسعه محلی از SQLite استفاده میکنید ولی برای محیط توسعه بازاری خودتون از یک دیتابیس دیگه استفاده میکنید. به همین خاطر بهتره که هم در محیط توسعه محلی و هم در محیط توسعه بازاری از یک دیتابیس استفاده بشه.
در این بخش ما یک پروژه جدید جنگو رو در یک محیط مجازی با دیتابیس SQLite شروع میکنیم و سپس به Docker و PostgreSQL سوییچ میکنیم.
تنظیمات جنگو
در ترمینال خودتون به دایرکتوری کد هاتون برید و یک دایرکتوری جدید ایجاد کنید که من اسم دایرکتوری خودم رو " part-3 " میذارم ولی شما میتونید از هر اسم دیگه ای برای دایرکتوری خودتون استفاده کنید و سپس وارد دایرکتوری جدیدتون بشید تا کار رو با هم ادامه بدیم:
Shell
# Windows
> cd desktop\code
> mkdir part-3
> cd part-3
# macOS
% cd ~/desktop/code
% mkdir part-3
% cd part-3
حالا محیط مجازی خودمون رو ایجاد میکنیم و جنگو رو نصب کرده و کار رو استارت میزنیم:
Shell
> pipenv install django~=4.0.0
> pipenv shell
الان میتونیم یک پروژه جدید به نام " django_project " (یا هر اسمی که دلخواه خودتون باشه) ایجاد کنیم، سپس دستور "migrate" رو اجرا کنیم تا دیتابیس اولیه راه اندازی بشه و نهایتا برای اطمینان از صحت همه مراحل قبلی با استفاده از دستور "runserver" وب سرور خودمون رو راه اندازی کنیم:
Shell
(part-3-fVXlZ5NX) > django-admin startproject django_project .
(part-3-fVXlZ5NX) > python manage.py migrate
(part-3-fVXlZ5NX) > python manage.py runserver
حالا اگه به آدرس " http://127.0.0.1:8000 " برید، میتونید صفحه خوش آمد گویی جنگو رو ببینید که نشان از صحت مراحل طی شده داره. با فشار دادن کلید های Ctrl+C سرور رو متوقف کنید.
معمولا تا زمانیکه یک User model سفارشی برای پروژه های جدید پیکربندی نکردیم، توصیه نمیشه که دستور "migrate" رو اجرا کنید چون در این صورت جنگو User model پیشفرض خودش رو به دیتابیس پیوست میده که بعدا اصلاح کردنش سخت میشه. درباره این موضوع در آینده به خوبی صحبت میکنیم ولی از اونجاییکه این بخش بر روی چیز دیگه ای تمرکز داره، استفاده از User model پیشفرض این دفعه استثنائا موردی نداره.
Docker
قبل از اینکه سوییچ کنیم روی داکر، اول از محیط مجازی خارج میشیم و بعدش در دایرکتوری اصلی، فایلهای Dockerfile و docker-compose.yml رو ایجاد میکنیم که قراره تا ایمیج و کانتِینر ما رو کنترل کنند:
Shell
(part-3-fVXlZ5NX) > exit
>
بعد از اینکه فایل Dockerfile رو ایجاد کردید کد های زیر رو بهش وارد کنید که با کد های بخش قبل یکسان هستن:
Dockerfile
# Pull base image
FROM python:3.10.4-slim-bullseye
# Set environment variables
ENV PIP_DISABLE_PIP_VERSION_CHECK 1
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
# Set work directory
WORKDIR /code
# Install dependencies
COPY Pipfile Pipfile.lock /code/
RUN pip install pipenv && pipenv install --system
# Copy project
COPY . /code/
قبل از اینکه بریم سراغ ایجاد کردن ایمیج، در دایرکتوری اصلی یک فایل dockerignore. درست کنید و موارد زیر رو بهش اضافه کنید:
dockerignore.
.git
.gitignore
حالا ایمیج اولیه رو با استفاده از دستور " . docker build " ایجاد میکنیم:
Shell
> docker build .
[+] Building 4.1s (11/11) FINISHED
...
=> => writing image sha256:737...
*: علت اینکه این روند ایندفعه در زمان کمتری نسبت به دفعه قبل اتفاق افتاد، به خاطر فایل های cache شده هستش.
نوبت به فایل docker-compose.yml میرسه که در بخش قبل هم دیدیم:
docker-compose.yml
version: "3.9"
services:
web:
build: .
command: python /code/manage.py runserver 0.0.0.0:8000
volumes:
- .:/code
ports:
- 8000:8000
Detached Mode
این دفعه قراره که کانتِینر رو در حالت جدا شده یا Detached Mode راه اندازی کنیم که لازمه برای اینکار " d- " یا " detach- " رو به انتهای دستور اضافه کنیم:
Shell
> docker-compose up -d
در این حالت، کانتینر ها در بک گراند اجرا میشن که این بدین معنی هستش که نیازی نیست یه ترمینال جداگانه دیگه برای اجرای دستورات بازکنیم و میتونیم فقط با یکی کارمون رو جلو ببریم. عیبی هم که داره اینه که اگر یه اِروری رخ بده، توی خروجی برای ما نشون داده نمیشه. پس در هر نقطه ای از این فصل از دوره احساس کردید که خروجی های شما با چیزی که اینجا میگیم تفاوت داره، بهتره که دستور " docker-compose logs " رو اجرا کنید و باگ های پیش اومده رو رفع کنین.
برای اطمینان از صحت مراحل قبل میتونید در مرورگر خودتون به آدرس " http://127.0.0.1:8000 " برید و صفحه خوش آمدگویی جنگو رو ببینید.
از اونجایی که ما در این فصل از دوره داریم با داکر کار میکنیم، لازمه تا دستورات خودمون رو از این به بعد با یه مقدمه شروع کنیم که قالب کلی رو به این صورت در میاره : " docker-compose exec [service] [command] " ؛ بجای [service] اسم سرویس خودمون یعنی " web " رو قرار میدیم که در فایل docker-compose.yml تعیینش کردیم و بجای [command] دستوری که میخواهیم اجرا بشه رو قرار میدیم. برای نمونه: بمنظور ایجاد یک حساب کاربری ارشد یا superuser ، بجای تایپ کردن دستور " python manage.py createsuperuser " باید از دستور زیر استفاده کنیم :
Shell
> docker-compose exec web python manage.py createsuperuser
***: اگر از رایانه های جدیدتر اَپل که مبتنی بر تراشه M1 هستن استفاده میکنید، دستور بالا ممکنه براتون این اِرور رو نشون بده:" django.db.utils.OperationalErro: SCRAM authentication requires libpq version 10 or above " ، برای حل این مشکل کافیه که خط اول در فایل Dockerfile رو به شکل زیر تغییر بدید:
Dockerfile
# Pull base image
FROM –platform=linux/amd64 python:3.10.4-slim-bullseye
...
بعد از اجرای دستور موردنظر، جنگو از ما میخواد که یکسری مشخصات رو بهش بدیم. من برای username از "admin" و برای email از "admin@email.com" و برای password از "codingcogs" استفاده میکنم ولی شما میتونید از هر مشخصات دیگه ای استفاده کنید.
حالا برای دسترسی به پنل اَدمین به آدرس " http://127.0.0.1:8000/admin " میریم و با وارد کردن مشخصات لازم وارد حساب خودمون میشیم. دقت کنید که در قسمت بالا و سمت راست میتونید username خودتون رو مشاهده کنید که برای من "ADMIN" هستش:
اگر روی Users کلیک کنید به صفحه کاربران هدایت میشید که میتونید اونجا حساب کاربری خودتون و حسابهای دیگه رو هم ببینید که فعلا فقط حساب اَدمین توی لیست حاضر هستش:
در این مرحله از کار لازمه تا به یکی از جنبه های فوق العاده داکر اشاره کنیم:
تا الان ما دیتابیس خودمون که به صورت یک فایل با عنوان db.sqlite3 در داخل داکر نشون داده میشه رو بروزرسانی میکردیم که به لطف تنظیمات volumes در پیکربندی فایل docker-compose.yml ، این تغییرات به فایل db.sqlite3 حاضر در رایانه ما هم کپی میشد و هر دو فایل در هر مرحله ای از کار با هم همگام جلو میرفتن. یعنی اگه شما الان از داکر کاملا خارج بشید و سپس محیط مجازی حاضر در رایانه خودتون رو با دستور " pipenv shell" راه اندازی کنید و سپس دستور " python manage.py runserver " رو اعمال کنید، میبینید که پنل اَدمین بدون هیچ تغییری نشون داده میشه و دقیقا مشابه همون چیزی هستش که داخل کانتینر باهاش سرو کار داشتید، چون دیتابیس ها دقیقا یکسان هستن و همیشه با هم همگام جلو میرن!
PostgreSQL
حالا وقتشه که سوییچ کنیم به PostgreSQL که برای این کار باید مراحل زیر رو طی کنیم:
- ایجاد یک کانتِینر اختصاصی برای دیتابیس جدید یعنی PostgreSQL
- بروزرسانی پیکربندی DATABASE در فایل settings.py
- نصب کردن یک آداپتورِ دیتابیس به نام psycopg2 به منظور ایجاد ارتباط بین پایتون و PostgreSQL
قبل از شروع، ابتدا کانتِینر رو با دستور " docker-compse down " متوقفش میکنیم:
Shell
> docker-compose down
سپس در وهله اول میریم سراغ فایل docker-compose.yml و یک سرویس جدید به نام db ایجاد میکنیم. این بدین معنا هستش که ما دو کانتِینر جداگانه خواهیم داشت که داخل داکر در حال اجرا خواهند بود: یکی web که برای سرور محلی جنگو هستش و یکی هم db که برای دیتابیس PostgreSQL هستش.
سرویس web برای اجرا شدن به سرویس db اتکا خواهد داشت که این کار رو با اضافه کردن " depends_on " به فایل docker-compose.yml نشون میدیم، این بدین معنی هستش که سرویس db قبل از سرویس web راه اندازی میشه.
همچنین داخل سرویس db مشخص میکنیم که از کدوم ورژن PostgreSQL قراره استفاده کنیم. که به هنگام نگارش این دوره، نسخه 13 عرضه شده و ما هم از همین نسخه استفاده میکنیم.
دقت کنید که کانتِینر های داکر بدون دوام و زودگذر هستن یعنی وقتی کانتینر متوقف میشه، همه اطلاعات هم از دست میرن که برای حل این مشکل و تداوم داده ها از volumes استفاده میکنیم. در حال حاضر و داخل سرویس web یک volume داریم که کد روی رایانه ما رو به کانتِینر متصل میکنه و بلعکس. اما برای سرویس db که منحصر به دیتابیس PostgreSQL هستش، اصلا volume تخصیص داده نشده که در نتیجه وقتی کانتِینر متوقف بشه همه اطلاعات هم از دست میرن! راه حلش اینه که یک volume روی این سرویس به اسم "postgres_data" ایجاد کنیم و متصلش کنیم به یک دایرکتوری اختصاصی داخل کانتینر که در لوکِیشن: "/var/lib/postgresql/data/" قرار داره؛ همچنین یک volume دیگه هم خارج کانتینر معین میکنیم.
یجورایی میشه گفت که قضیه یکم پیچیده شد ولی توضیح کاملش هم از حوصله این فصل از دوره خارج هستش چون ما روی جنگو تمرکز داریم نه داکر. ولی در کل میشه اینطوری گفت که کانتِینر ها داده ها رو بصورت متداوم نگه داری نمیکنن؛ پس فرقی نمیکنه که چه بخواهیم کد های خودمون رو نگه داری کنیم و چه اطلاعات مربوط به دیتابیس رو، باید واسه هرکدوم یک volume تخصیص بدیم و گرنه وقتیکه کانتِینر متوقف بشه همشون از دست میرن. اگر به توضیحات فنی بیشتری راجع به این قضیه نیاز دارید توصیه میکنم که مستندات داکر رو درباره volumes بخونید.
حالا نوبت به این میرسه که به قسمت environment در تنظیمات سرویس جدیدمون یعنی db، یک متغیر اضافه کنیم :" POSTGRES_HOST_AUTH_METHOD=trust ". این متغیر تحت عنوان trust authentication فعالیت میکنه و علت اضافه کردنش به سرویس جدیدمون اینه که دیتابیس های بزرگ اغلب کاربرای زیادی دارن و به همین خاطر توصیه میشه که به هر کاربر بصورت مجزا اجازه دسترسی به دیتابیس داده بشه، ولی از اونجاییکه الان فقط یک کاربر داریم و اونم خودمون هستیم، اعمال تنظیم بالا انتخاب خوبیه چون دیگه میتونیم بدون نیاز به رمز عبور به دیتابیس متصل بشیم و کار توسعه برامون راحت تر بشه.
نهایتا فایل docker-compose.yml به این شکل در میاد:
docker-compose.yml
version: "3.9"
services:
web:
build: .
command: python /code/manage.py runserver 0.0.0.0:8000
volumes:
- .:/code
ports:
- 8000:8000
depends_on:
- db
db:
image: postgres:13
volumes:
- postgres_data:/var/lib/postgresql/data/
environment:
- "POSTGRES_HOST_AUTH_METHOD=trust"
volumes:
postgres_data:
حالا نوبت میرسه به تنظیمات پروژه که برای اینکار باید فایل django_project/settings.py رو به نحوی بروزرسانی کنیم تا بجای SQLite از PostgreSQL استفاده کنه. این فایل رو در text editor خودتون باز کنید و یکمی به سمت پایین اِسکرول کنید تا به قسمت DATABASES برسید. تنظیمات فعلی به شکل زیر هستن:
Code
# django_project/settings.py
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
همینطوریکه مشاهده میکنید، جنگو بصورت پیشفرض موتور پایگاه داده رو روی sqlite3 تنظیم کرده و بهش اسم " db.sqlite3 " رو داده و در BASE_DIR قرارش داده که در واقع همون دایرکتوری پایه ما هستش.(منظور از دایرکتوری پایه همون دایرکتوری part-3 هستش که در ابتدای کار ایجاد کردیم.)
برای سوییچ کردن روی PostgreSQL باید پیکربندی ENGINE رو بروزرسانی کنیم. PostgreSQL نیازمند تعیین NAME، USER، PASSWORD، HOST و PORT هستش. برای راحتی کار به سه تای اولی postgres میدیم، به HOST اسم سرویسمون یعنی db رو میدیم که در فایل docker-compse.yml تنظیمش کردیم، و PORT رو هم روی "5432" میذاریم که پورت پیشفرض PostgreSQL هستش.
نهایتا فایل بروزرسانی شده django_project/settings.py به شکل زیر درمیاد:
Code
# django_project/settings.py
DATABASES = {
"default": {
"ENGINE": "django.db.backends.postgresql",
"NAME": "postgres",
"USER": "postgres",
"PASSWORD": "postgres",
"HOST": "db",
"PORT": 5432,
}
}
حالا میرسیم به آخرین مرحله از کار ولی قبل از اینکه مستقیم بریم سر وقت نصب کردن psycopg2، اجازه بدید که کمی در مورد اینکه یک زبان برنامه نویسی مثل پایتون چطور میتونه با یک دیتابیس مثل PostgreSQL ارتباط برقرار کنه حرف بزنیم.
دیتابیس PostgreSQL دیتابیسی هستش که تقریبا تمامی زبانهای برنامه نویسی میتونن ازش استفاده کنن. اما این سوال پیش میاد که یک زبان برنامه نویسی چجوری میتونه به دیتابیس متصل بشه؟
پاسخ این سوال آداپتورهای دیتابیس هستن که Psycopg هم یکی از این آداپتورهاست و میشه گفت محبوبترین آداپتور دیتابیس برای پایتون هستش.
اخیرا psycopg3.0 عرضه شده ولی از اونجائیکه هنوزم پکیج ها و هاست های زیادی روی psycopg2 تمرکز دارن، ما هم از این نسخه استفاده میکنیم. فقط دقت کنید که دو نسخه از Psycopg2 در دسترس هستش:
- نسخه اول: psycopg2
- نسخه دوم: psycopg2-binary
ما در این فصل از ورژن باینِری استفاده میکنیم، چون استفاده کردن ازش راحت تره و برای اکثر وبسایتها بدون مشکل کار میکنه. برای استفاده از نسخه غیر باینِری لازمه که چند تا مرحله اضافی تر برای تنظیم و پیکربندیش وقت بذاریم و فقط واسه وبسایتهای بزرگ از این نسخه استفاده میشه.
قبل از شروع ابتدا کانتِینر رو دوباره راه اندازی میکنیم:
Shell
> docker-compose up -d
حالا Psycopg رو با استفاده از Pipenv در داکر نصب میکنیم:
Shell
> docker-compose exec web pipenv install psycopg2-binary==2.9.3
حالا شاید براتون این سوال پیش بیاد که چرا داریم داخل داکر نصبش میکنیم و بصورت محلی(Local) روی رایانه خودمون نصبش نمیکنیم؟
پاسخ کوتاهی که میشه به این سوال داد اینه که نصب کردن پکیج های نرم افزاری داخل داکر و بازسازی دوباره ایمیج، ما رو از مشکلات احتمالی که در اثر تداخلات فایل Pipfile.lock بوجود میان دور نگه میداره.
توجه داشته باشید که فایلِ Pipfile.lock تولید شده، بشدت به سیستم عامل مورد استفاده بستگی داره.
ما همون اول کار سیستم عامل مورد استفاده خودمون در داکر که شامل پایتون نسخه 3.10 میشد رو مشخص کردیم. ولی اگه حالا بخواهیم psycopg2 رو با دستور " pipenv install psycopg2-binary==2.9.3 " بصورت محلی روی رایانه خودمون که محیط متفاوتی داره نصب کنیم، فایلِ Pipfile.lock حاصل هم متفاوت خواهد بود. همونطوریکه کمی قبل تر مشاهده کردید، ما volumes رو در فایل docker-compose.yml تعریف کردیم که قراره بصورت خودکار فایلهای محلی رو با داکر همگام کنن و در نتیجه باعث میشن تا فایلِ Pipfile.lock که روی رایانه ما وجود داره، نسخه ای از خودش رو که در داکر موجود هست رو بازنویسی کنه. در نتیجه کانتِینر ما فایلِ Pipfile.lock اشتباهی رو اجرا میکنه!
یک روش برای اجتناب از این مشکل اینه که بجای نصب کردن پکیج ها بصورت محلی، اونارو در داخل داکر نصبشون کنیم.
خب حالا وقتشه دوباره بریم به آدرس " http://127.0.0.1:8000 " و ببینیم که همه چیز درست کار میکنه یا نه ؟
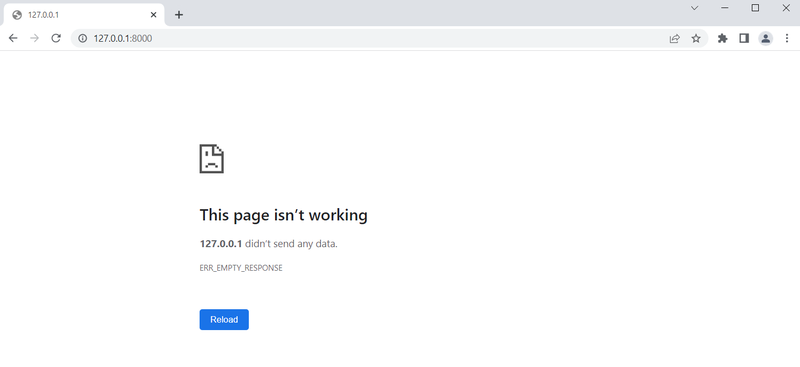
نه! مثل اینکه مشکل داریم.
قبل تر اشاره ای به این داشتیم که اگه " d- " یا " detach- " رو به انتهای دستور " docker-compose up " اضافه و اجرا کنید، کانتِینر ها در بک گراند اجرا میشن و دیگه ترمینال شما اشغال نمیشه. ولی اگر مشکلی هم بوجود بیاد شما نمیتونید این مشکل رو توی ترمینال خودتون ببینید و باید دستور " docker-compose logs " رو وارد کنید. پس این دستور رو توی ترمینال خودتون وارد کنید تا گزارشی از سمت داکر رو درباره مشکل یا مشکلات بوجود اومده، در ترمینال خودتون ببینید:
Shell
> docker-compose logs
...
part-3-web-1 | django.core.exceptions.ImproperlyConfigured: Error loading psycopg2 module: No module named 'psycopg2'
...
*: خطوط زیادی در ترمینال ظاهر میشن که فقط قسمت مربوط به اِرور پیش اومده رو در بالا آوردیم.
ما پکیج جدیدی رو نصب کردیم که منجر به بروزرسانی هایی در فایلهای Pipfile و Pipfile.lock شد و انتظار داریم که داکر با عنایت به این فایلها، ایمیج ما رو بطور خودکار بازسازی کنه؛ ولی اگر به خط انتهایی فایل Dockerfile دقت کنید: " /COPY . /code " ، متوجه میشید که فایلها فقط دارن کپی میشن و زیر ساختِ ایمیج ما اصلا تغییری نمیکنه یا به عبارتی: ایمیج خودشو بازسازی نمیکنه، مادامی که ما مجبورش کنیم! این کار رو میتونیم با اضافه کردن " build– " به انتهای دستور " docker-compose up -d " انجام بدیم.
این روند در طول این فصل از دوره مدام تکرار میشه.
ابتدا کانتِینر رو متوقف و بعدا دستور مذکور رو اجرا میکنیم:
Shell
> docker-compose down
> docker-compose up -d –build
*: یکم زمان میبره.
حالا اگه دوباره در مرورگر خودتون به آدرس " http://127.0.0.1:8000 " برید، با صفحه خوش آمدگویی جنگو مواجه میشید و این یعنی اِرور موردنظر حل شده و جنگو با موفقیت از طریق داکر به PostgreSQL متصل شده!
دیتابیس جدید
دیتابیس فعلی ما خالیه و علت این قضیه اینه که دیگه دیتابیس ما SQLite نیست و سوییچ کردیم روی PostgreSQL . برای اطمینان از این قضیه میتونید دستور " docker-compose logs " رو اجرا کنید، که منجر به دریافت پیام هایی از قبیل: " You have 18 unapplied migration(s) " میشه:
Shell
> docker-compose logs
..
part-3-web-1 | You have 18 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes,
sessions.
...
برای اینکه این قضیه کاملا براتون واضح بشه میتونید به آدرس " http://127.0.0.1:8000/admin " برید و سعی کنید تا با مشخصات حساب اَدمین خودتون که قبلا ایجاد کردید، وارد بشید.
مشخصه که در همون ابتدای کار با اِرور " /ProgrammingError at /admin " مواجه میشید و اصلا کار به جایی نمیکشه که بتونید حتی مشخصات خودتون رو وارد کنید!

برای حل این مشکل میتونیم هر دو دستور " migrate " و " createsuperuser " رو متعاقبا در داخل داکر که به دیتابیس PostgreSQL دسترسی خواهد داشت، اجرا کنیم.
Shell
> docker-compose exec web python manage.py migrate
> docker-compose exec web python manage.py createsuperuser
حالا دوباره باید مشخصاتی رو برای حساب اَدمین وارد کنیم که من مثل دفعه قبل username رو "admin" و email رو "admin@email.com" و password رو "codingcogs" انتخاب میکنم ولی شما میتونید از هر مشخصات دیگه ای که دلخواهتون هست استفاده کنید.
حالا در مرورگر خودتون دوباره به آدرس " http://127.0.0.1:8000/admin " برید و مشخصات حساب اَدمین جدید خودتون رو وارد کنید و وارد بشید.
میتونید روی Users کلیک کنید تا مطمئن بشید که فقط و فقط یک حساب کاربری اَدمین وجود داره و خبری از حساب قبلی نیست:
خب! کار ما رسما تمومه و وقتشه که دیگه کانتِینر های خودمون رو متوقف کنیم:
Shell
> docker-compose down
Git
وقتشه که همه تغییرات رو با Git ذخیره کنیم.
یک ریپازیتوری جدید راه اندازی کنید و وضعیت فعلی رو چک کنید:
Shell
> git init
> git status
در ادامه و قبل از ایجاد اولین commit بهتره که یک فایل gitignore. دردایرکتوری پایه ایجاد کنیم و خطوط زیر رو بهش اضافه کنیم:
gitignore.
__pycache__/
db.sqlite3
.DS_Store # Mac only
دوباره دستور " git status " رو اجرا کنید تا مطمئن بشید که مواردی که توی فایل gitignore. بهشون اشاره کردیم، دیگه توسط Git پیگیری نمیشن و بعدش همه تغییرات رو اضافه کنید و نهایتا commit خودتون رو به همراه یک پیغام کوچک اعمال کنید:
Shell
> git status
> git add .
> git commit -m “part-3”
راه اندازی داکر در هر بار شروع به کار با سیستم
قرار نیست که حتما با یک نفس تا آخر دوره برید! واسه همین هر وقت سیستم خودتون رو خاموش کردید و بعد از مدتی استراحت برگشتید تا پروژه ای رو ادامه بدید، کافیه که مراحل زیر رو برای راه اندازی مجدد داکر و کانتِینر خودتون انجام بدید:
1- نرم افزار Docker Desktop رو که قبلا دانلود و نصبش کردید رو باز کنید.
2- در ترمینال خودتون به مسیری برید که کد پروژه فعلی شما در اون حضور داره.
برای مثال من اگر در دستکتاپ خودم یک دایرکتوری به نام " code " داشته باشم و داخل این دایرکتوری یک فولدر جداگانه با نام " main-project " برای پروژه فعلی اختصاص داده باشم، باید به مسیر زیر برم تا به کد پروژه مورد نظرم دسترسی داشته باشم:
Shell
# Windows
> cd desktop/code/main-project
# MacOS
% cd desktop\code\main-project
3- با استفاده از دستور: " docker-compose up -d " کانتِینر خودتون رو در حالت detach راه اندازی کنید:
Shell
> docker-compose up -d
4- در انتهای کار و بمنظور متوقف کردن کانتِینر از دستور: " docker-compose down " استفاده کنید.
جمع بندی
سوییچ کردن از دیتابیس SQLite به PostgreSQL برای بسیاری از توسعه دهنده ها یک قدم بزرگه که در این بخش در راستای نشون دادن نحوه تعامل Docker و PostgreSQL روی یک پروژه جنگو صورت گرفت.
نکته کلیدی اینه که با داکر دیگه لازم نیست که صرفا داخل یک محیط مجازی محلی کار کنیم، چون حالا داکر هم محیط مجازی ما هستش، هم دیتابیس ما و هم چیزای دیگه ای که ممکنه زمانی لازممون بشن. میزبان قدرتمندی مثل داکر عملاً جانشین سیستم عامل رایانه ما میشه و ما میتونیم داخلش کانتِینر های متعددی رو به وب اَپلیکیشن ها و دیتابیس های خودمون اختصاص بدیم و در صورت نیاز این کانتِینر ها رو ایزوله کنیم و جداگانه اجراشون کنیم و یا بلعکس.
در بخش بعدی با همدیگه پروژه کتابفروشی آنلاین رو که پروژه اصلی این فصل از دوره هست رو استارت میزنیم.