انتخاب الگوریتم درست برای یادگیری ماشینی
انتخاب الگوریتم صحیح و مناسب در یادگیری ماشین
وقتیکه در مواجه با یک مشکل داده محور نوبت به توسعه راه حل های یادگیری ماشین میرسد، مهم است به این نکته اشاره شود که اغلب اوقات، هیچ راه حل همه فن حریفی وجود ندارد که مناسب برای تمامی مشکلات داده ای باشد. با عنایت به اینکه الگوریتم های زیادی در زمینه ی یادگیری ماشین وجود دارند، انتخاب الگوریتم مشخصی که منجر به دستیابی به یک مدل مناسب برای مشکل داده محور مورد نظر باشد، یک نقطه ی عطف در روند توسعه محسوب میشود.
پیروی از مراحل زیر می تواند کمک شایانی به محدود کردن دامنه تصمیم گیری در خصوص الگوریتم های مناسب کند:
1) شناخت کلی داده: با توجه به اینکه دادهها کلید توسعه ی هر گونه مدل یادگیری ماشین میباشند، داشتن شناخت صحیح از داده های در دست همیشه اولین قدم در خصوص فیلتر کردن هر الگوریتمی است که قابلیت پردازش داده موردنظر را ندارد. به عنوان مثال؛ با توجه به کمیت و ویژگیهای یک جامعهی هدف و مشاهداتی که روی آن صورت گرفته و منجر به دستیابی به یک مجموعه دادهی کوچک شده اند، میتوان تعیین کرد که آیا الگوریتمی قادر به تولید نتایج مطلوب در خصوص مجموعه دادهی کوچک ما میباشد یا خیر؟!
2) تعیین دستهی مسائل دادهمحور: مطابق نموداری که در ادامهی مطالب خواهید دید؛ در این مرحله با تجزیه و تحلیل دادههای ورودی خود باید مشخص کنید که آیا مجموعه دادهی در دسترس، دارای یک ویژگی هدفمحور (ویژگیای که قصد دارید تا مقادیر آن مدل سازی و پیش بینی شود) می باشد یا خیر؟! مجموعه دادههایی(Datasets) که دارای یک ویژگی هدفمحور(Target feature) میباشند را با عنوان دادههای برچسبدار(Labeled data) میشناسیم و در پردازش آنها از الگوریتمهای یادگیری نظارتشده(Supervised learning) استفاده میکنیم(مورد A). از سوی دیگر، مجموعه دادههایی که ویژگی هدفمحوری ندارند را با عنوان دادههای بدون برچسب(Unlabeled data) میشناسیم و در پردازش آنها از الگوریتمهای یادگیری بدوننظارت(Unsupervised learning) استفاده میکنیم(مورد B). علاوه بر این، فُرم دادههای خروجی(خروجی موردانتظار شما از مدل) نیز نقشی کلیدی در تعیین الگوریتم های مورد استفاده دارد. یعنی اگر لازم است که خروجی دریافتی از مدل، یک عدد پیوسته(Continuous number) باشد؛ پس با یک مسئلهی رِگرسیونی سر و کار داریم(مورد D). اما اگر لازم داریم که خروجی دریافتی بصورت یک مقدار گسسته(Discrete value) باشد(مثل مجموعهای از کتگوریها)، باید در برخورد با مسئلهی موردنظر یک رویکرد طبقهبندی شده اتخاذ کنیم(مورد C). نهایتا هم اگر قرار بر این باشد که بر پایه مشاهدات صورت گرفته یک خروجی شهودی از مدل پیاده شده دریافت کنیم، مسئلهی موردنظر از جنس خوشهبندی خواهد بود(مورد E):
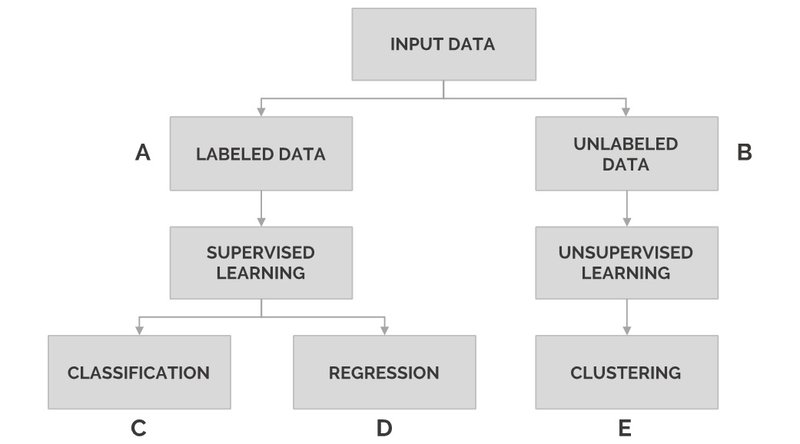
*: توجه داشته باشید که تقسیمبندی وظایف با جزئیات بیشتری در بخش یادگیری تحتنظارت و بدوننظارت، در این فصل بررسی خواهند شد.
3) انتخاب مجموعهای از الگوریتمها: پس از طی کردن مراحل فوق، میتوانید یک لیست فیلترشده از الگوریتم هایی را که عملکرد خوبی نسبت به داده های ورودی داشته و قادر به ارائهی نتایج مطلوبی هستند را تهیه کرده و سپس بسته به منابع و محدودیت های زمانی خود، الگوریتم های مناسبی را از این لیست انتخاب کرده و بر روی مسئلهی موردنظرتان آزمایش کنید. توجه داشته باشید که همواره محطاتانه ترین و ایدهآل ترین رویکرد آن است که بیش از یک الگوریتم را امتحان کنید.