مثال 1.01: بارگذاری یک دیتاسِت نمونه و تشکیل ماتریسهای هدف و فیچر
توجه:
اکثر مثال ها و تمرینات این دوره عمدتاً در نوتبوکهای Jupyter توسعه داده میشوند. توصیه می شود که یک Notebook جداگانه برای تکالیف مختلف داشته باشید. همچنین، برای بارگذاری دیتاست نمونه، از کتابخانه seaborn استفاده خواهد شد، زیرا داده ها را به صورت جدولی نمایش میدهد. روشهای دیگری برای بارگذاری دادهها در بخش های بعدی معرفی خواهند شد.
در این مثال، یک دیتاست با نام: " tips " (به معنی: اَنعام)، را از کتابخانه seaborn بارگذاری میکنیم و از روی آن، ماتریس فیچرها و ماتریس هدف را ایجاد میکنیم.
توجه:
بمنظور تکمیل مثال ها و تمرینات این فصل، مطمئن شوید که پایتون نسخهی 3.7، Seaborn نسخهی 0.9، Jupyter نسخهی 6.0، Matplotlib نسخهی 3.1، NumPyنسخهی 1.18 و Pandas نسخهی 0.25 روی سیستم شما نصب باشد.
بمنظور تکمیل این مثال، مراحل زیر را بهترتیب دنبال میکنیم:
1- ابتدا یک دفترچه یادداشت Jupyter باز کنید. بدین منظور، در Command Prompt یا Terminal به مسیر موردنظر خودتان رفته و دستور زیر را اجرا کنید:
Terminal
jupyter notebook
2- دیتاست tips را با استفاده از کتابخانه seaborn بارگیری کنید. برای انجام این کار، باید کتابخانه seaborn را فراخوانی کنید و سپس از تابع ()load_dataset استفاده کنید، همانطور که در کد زیر نشان داده شده است:
Jupyter Notebook
import seaborn as sns
tips = sns.load_dataset('tips')
tips
همانطوریکه در کد بالا مشاهده میکنید؛ بعد از فراخوانی کتابخانهی Seaborn، یک نام مستعار: " sns " به آن اختصاص دادیم تا استفاده از آن در ادامهی کار تسهیل شود.
تابع ()load_dataset دیتاست را از یک ریپازیتوری آنلاین بارگیری میکند، سپس دادههای این دیتاست در متغیری به نام: " tips " ذخیره می شود و نهایتا آنرا مشاهده میکنیم:
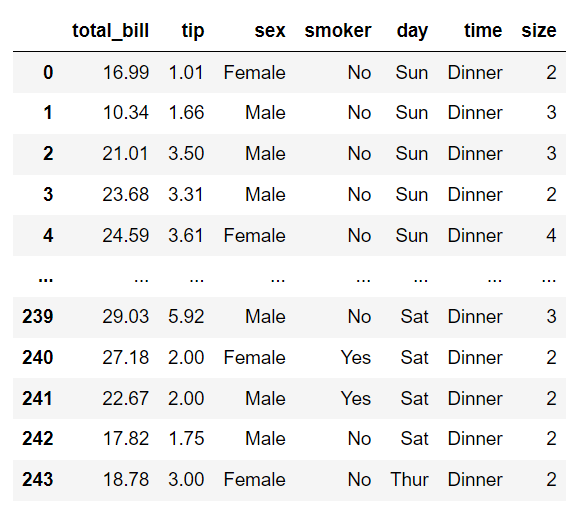
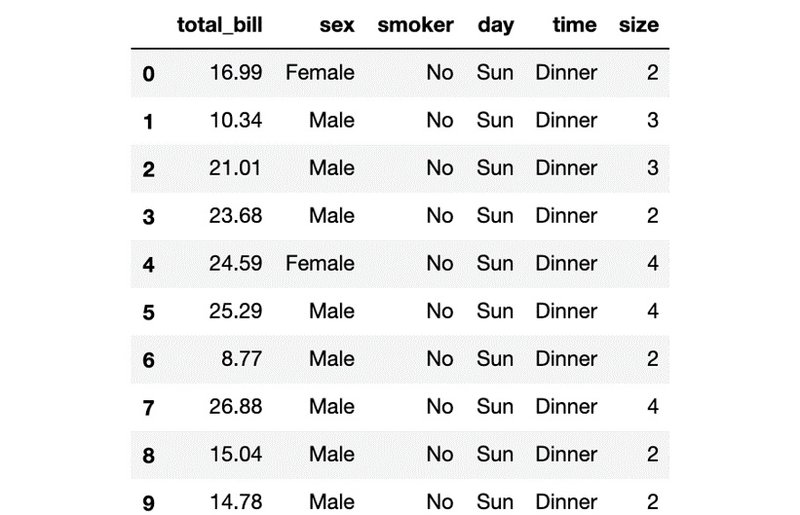
3- فیچر هدف ما در دیتاست فوق، " tip " میباشد. به همین خاطر در ابتدا متغیری به نام: " X " ایجاد کرده و همهی فیچرها به غیر از فیچرِ موردهدف(tip) را با استفاده از تابع ()drop داخل آن ذخیره میکنیم. سپس، 10 نمونهی اول را چاپ میکنیم:
Jupyter Notebook
X = tips.drop('tip', axis=1)
X.head(10)
لازم به ذکر است که پارامترِ axis در قطعه کد قبل نشان می دهد که آیا می خواهید فیچر موردهدف را از بین ردیفها (axis = 0) حذف کنید یا از بین ستون ها (axis = 1).
نهایتا، خروجی چاپ شده باید به صورت زیر باشد:
4- ابعاد متغیر جدید را با استفاده از دستور زیر چاپ کنید:
Jupyter Notebook
X.shape
خروجی به صورت زیر خواهد بود:
Jupyter Notebook
(244, 6)
مقدار اول، تعداد نمونه های موجود در دیتاست جدیدرا نشان می دهد(244)؛ در حالی که مقدار دوم تعداد فیچرها (6) را نشان می دهد.
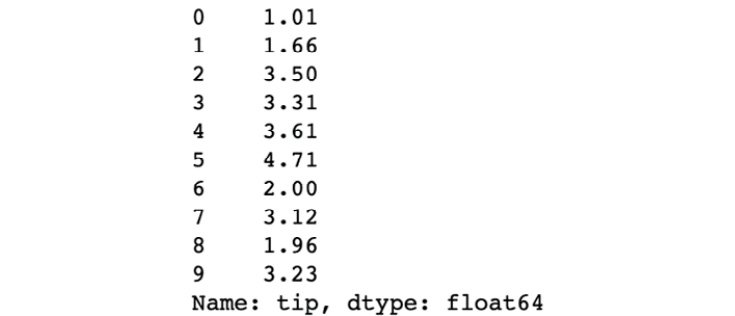
5- حالا برای اینکه مقادیر ثبت شده برای فیچر هدف را ذخیره کنیم، متغیری به نام: " Y " تعریف میکنیم و تمامی مقادیری که در ستونِ: " tip " از دیتاست موردنظر ثبت شدهاند را داخل این متغیر میریزیم. سپس، 10 نمونهی اول را چاپ میکنیم:
Jupyter Notebook
Y = tips['tip']
Y.head(10)خروجی چاپ شده باید به صورت زیر باشد:
6- ابعاد متغیر جدید خود را با استفاده از دستور زیر چاپ کنید:
Jupyter Notebook
Y.shape
خروجی به صورت زیر خواهد بود:
Jupyter Notebook
(244,)
و در این مرحله از کار میتوان گفت که ماتریسِ فیچرها و ماتریس هدف را با موفقیت ایجاد کردهایم.
به طور کلی روشی که برای نمایش دادهها ترجیح داده میشود، استفاده از جداول دو بعدی است که در آن ردیفها نشان از تعداد موارد نمونه برداری شده داشته و ستونها نیز نشان دهندهی ویژگیهای آن نمونهها(instances) هستند که معمولاً به عنوان فیچر شناخته می شوند.
برای مشکلات دادهمحوری که نیازمند یکسری برچسبهای هدف یا به اصطلاح: " target lablels " میباشند، لازم هست که جدول داده به دو قسمت تقسیم شود: ماتریس فیچرها و ماتریس هدف.
ماتریس فیچرها، ماتریسی دو بعدی است که شامل مقادیر ثبت شده برای تمامی فیچر ها به غیر از فیچرِ موردهدف به اِزای تمام نمونههاست. از طرفی ماتریس هدف، ماتریسی 1 بعدی بوده و تنها شامل مقادیر ثبت شده برای فیچرِ موردهدف به اِزای تمام نمونههاست.