مثال ۱.۰۴: نرمالیزاسیون و استانداردسازی دادهها
مثال ۱.۰۴:
در این مثال سعی بر این خواهد بود تا به کمک دیتاست tips که قبلا هم با آن برخورد داشتیم، مباحث نرمالیزاسیون و استانداردسازی دادهها را پوشش دهیم؛ پس از همان دفترچه یادداشت Jupyter که برای مثال قبلی ایجاد کردیم استفاده میکنیم.
مراحل این مثال به شرح زیر میباشند:
1- با استفاده از متغیر tips که شامل کل دیتاست میباشد، دادهها را به کمک فرمول نرمالیزاسیون، نرمال کنید و در متغیر جدیدی به نام:" tips_normalized " ذخیره کنید. سپس 10 ردیف اول دیتاست نرمالایز شده را چاپ کنید:
Jupyter Notebook
tips_normalized = (tips - tips.min())/(tips.max()-tips.min())
tips_normalized.head(10)
خروجی بصورت زیر خواهد بود:
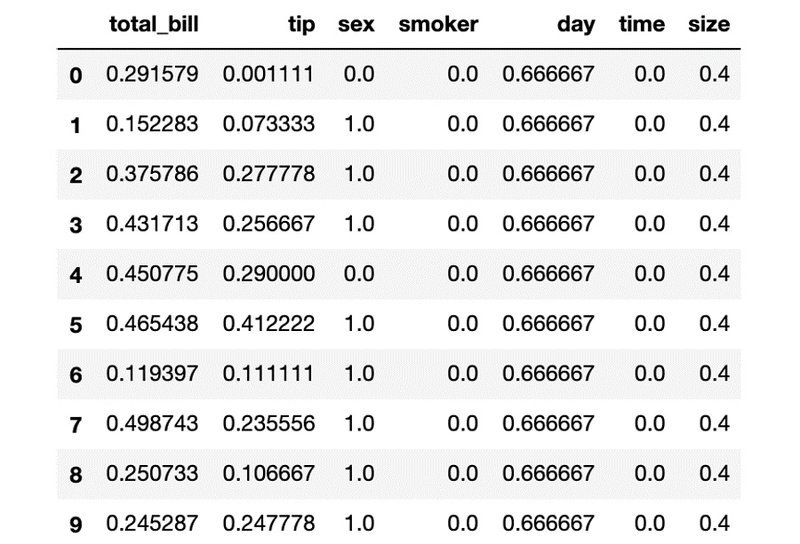
همانطوریکه در تصویر فوق مشاهده میکنید، همهی مقادیر به معادلهای متناظر با خودشان در محدودهی 0 تا 1 تبدیل شدهاند. با نرمالیزاسیون همهی فیچرها، این امکان برای مدل فراهم میشود که براساس فیچرهایی با مقیاس یکسان آموزش داده بشود.
2- مجدداً با استفاده از متغیر tips، دادهها را با استفاده از فرمول استانداردسازی، استاندارد کرده و در متغیری به نام:" tips_standardized "ذخیره کنید. سپس 10 ردیف اول دیتاست استاندارد شده را چاپ کنید:
Jupyter Notebook
tips_standardized = (tips - tips.mean())/tips.std()
tips_standardized.head(10)
خروجی به صورت زیر خواهد بود:
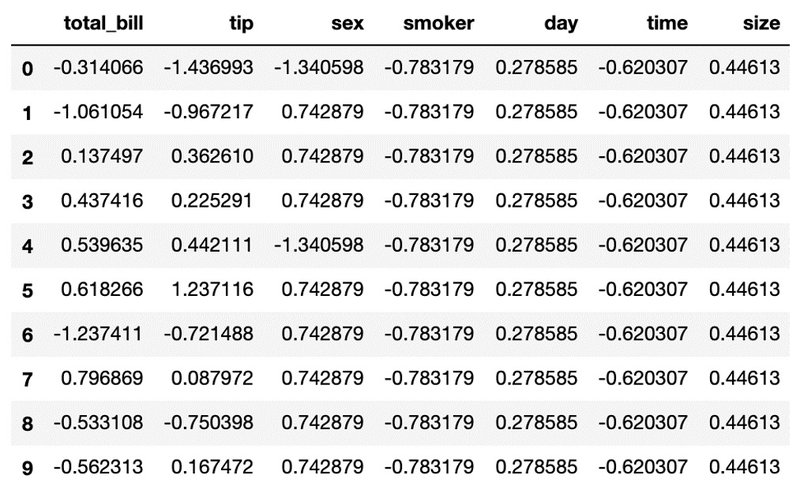
در مقایسه با نرمالیزاسیون، در روش استانداردسازی، مقادیر از یک توزیع گاوسی حول نقطهی صفر پیروی میکنند.
در این نقطه از کار میتوان گفت که ما با موفقیت، روشهای مقیاس بندی مجدد(Rescaling) را روی دیتاست خود پیاده کردیم.
جمع بندی:
با تکمیل این مثال، ما آخرین مرحله(Data Rescaling) از روند پیشپردازش دادهها را هم پوشش دادیم. این کار با هدف همگنسازی دادهها در راستای تسهیل درک دادهها توسط مدل و بر روی دیتاستی که مقیاسهای متفاوتی داشت، انجام شد. ناکامی در تکمیل این مرحله منجر به کند شدن سرعت روند آموزش و پدیدار شدن تاثیراتی منفی در عملکرد مدل خواهد شد.
دو روش بمنظور مقیاس بندی مجدد دادهها در این مبحث توضیح داده شد: نرمالیزاسیون و استانداردسازی؛ و دیدیم که روش نرمالیزاسیون، دادههای اولیه را به دادههایی بین 0 و 1 تبدیل میکند ولی روش استانداردسازی، دادهها را به فرم یک توزیع گاوسی با میانگین صفر و انحراف معیار 1 تبدیل میکند.
با عنایت بر اینکه هیچ قانونی برای انتخاب بهترین روش وجود ندارد، از این رو توصیه میشود که دادهها را با استفاده از دو یا سه روش، مجددا مقیاسبندی کنیم و سپس با آزمودن مدل روی دیتاست مقیاسبندی شدهی حاصل از هر روش، مناسبترین روش را انتخاب کنیم.