Outliers
دادههای پَرت یا Outliers
دادههای پرت، مقادیری هستند که از میانگینِ کل دادههای هم صنف خود فاصلهی زیادی دارند. این بدین معنی است که اگر تراکم دادههای یک فیچر را به فرم توزیع گاوسی درنظر بگیریم، دادههای پرت در دنبالههای آن قرار خواهند گرفت.
نکته:
به شرطی که تعداد اعداد بزرگتر و کوچکتر از میانگین با هم برابر باشند، توزیع گاوسی (معروف به توزیع نرمال) به شکل یک منحنی زنگوله-مانند خواهد بود.
دادههای پرت میتوانند گلوبال(Global) یا لوکال(Local) باشند.
- الف) Global Outliers:
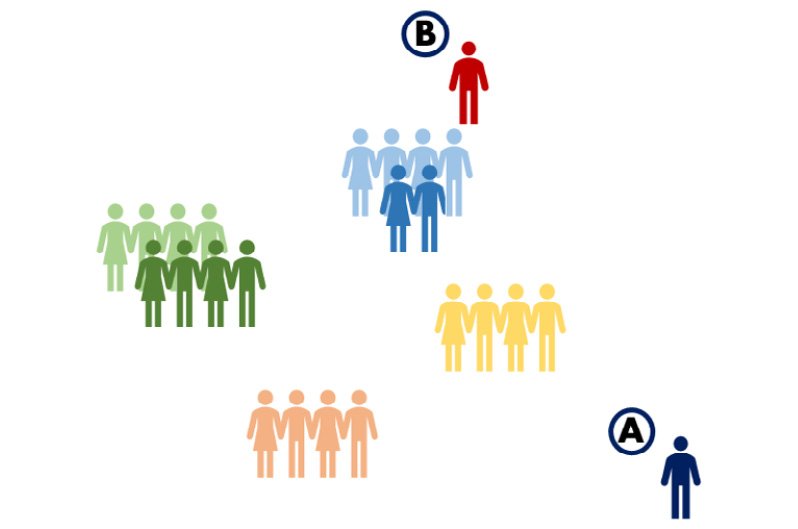
دادههای پرتی که در این دسته قرار میگیرند، تفاوت بسیار زیادی در مقایسه با کل دادههای حاضر در دیتاست دارند؛ بعنوان مثال فرض کنید که ما قصد بررسی دیتاست مربوط به ساکنین یک محله را داریم و در این بین به فردی برمیخوریم که 180 سال سن دارد! ما این مورد را در واقع به چشم یک دادهی پرت گلوبال میبینیم چون وجود یک فرد 180 ساله کلا غیرمنطقی بنظر میرسد و چنین فردی در هیچ زیرمجموعهای از دیتاست موردنظر نمیتواند جا بگیرد . (مورد A در تصویر زیر)
- ب) Local Outliers:
دادههای پرتی که در این دستهبندی قرار میگیرند، لزوما با کل دیتاست متفاوت نیستند و فقط با اعضای یک زیرمجموعه از این دیتاست تفاوت دارند؛ در مثالی که مطرح شد اگر دانش آموزان آن محله را بعنوان یک زیرمجموعه از کل محله درنظر بگیریم، و در این بین به دانش آموزی بربخوریم که 70 سال سن دارد! این مورد را باید به چشم یک دادهی پرت لوکال ببینیم. زیرا وجود یک دانش آموز 70 ساله چندان منطقی بنظر نمیرسد اما اینکه فردی در آن محله 70 سال سن داشته باشد کاملا منطقی است و اصلا چیز عجیبی به شمار نمیآید. (مورد B در تصویر زیر)
یک رویکرد ساده برای تشخیص دادههای پرت، بصریسازی دادهها با این هدف میباشد که آیا دادهها از توزیع گاوسی پیروی میکنند یا خیر؟! در صورتی که تفسیرات ما نشان از وجود دادههای پرت داشته باشند، ابتدا انحراف معیار(Standard Deviation) و میانگین(Mean) دادهها را محاسبه کرده و سپس دادههایی را که 3 الی 6 برابر انحراف معیار از میانگین فاصله داشته باشند را بعنوان دادههای پرت دسته بندی میکنیم. بعنوان مثال اگر میانگین دادههای یک دیتاستِ عددی، برابر 100 و انحراف معیار آنها برابر 10 باشد؛ دادههای بین 70 تا 130 را که به اندازهی 3 برابر انحراف معیار، بالاتر و پایینتر از میانگین قرار دارند را بعنوان دادههای پرت در نظر نمیگیریم ولی دادههایی را که زیر 70 یا بالای 130 باشند را بعنوان دادههای پرت درنظر میگیریم.
با وجود همهی موارد گفته شده، باز هم قاعدهای دقیق و کلّی برای یافتن دادههای پرت وجود ندارد و تصمیم اینکه بررسی دادههای عددی باید با چه نسبتی از انحراف معیار صورت گیرد، از مسئلهای به مسئله دیگر متفاوت است.
از طرفی دیگر تشخیص دادههای پرت به هنگام برخورد با فیچرهای متنی، پیچیدهتر میشود؛ زیرا در برخورد با دادههای متنی دیگر هیچ انحراف معیاری هم وجود ندارد که بشود از روی آن نتیجهگیری کرد. در این مواقع، شمارش تعداد دفعاتی که دستهی مشخصی از دادهها مرتبا ظاهر میشوند یا نه میتواند در تصمیمگیری ما برای چشمپوشی از آن دسته از دادهها کمک کند. به عنوان مثال؛ اگر در خصوص سایزبندی لباسهای یک دیتاست، سایز XXS داشته باشیم که کمتر از فقط 5% از کل سایزهای موجود را شامل میشود، در چنین موقعی شاید ضرورتی به نمایش این دسته مشخص از دادهها هم نداشته باشیم.
بعد از شناسایی دادههای پرت، نوبت به رسیدگی به آنها بر اساس سه رویکرد رایج زیر میرسد:
- حذف کردن دادههای پرت:
در صورتی که با دادههای پرت درست/واقعی یا به اصطلاح: " True Outliers " سروکار داشته باشیم، مثل سلبریتی معروفی که میانگین درآمد او 1 میلیون دلار در سال است و در بین دستهای از افراد قرار گرفته است که میانگین درآمد سالانه ای در حدود 50 هزار دلار در سال دارند؛ بهتر است که چنین دادههای پرتی را به طور کامل حذف کنیم تا از بروز هر گونه کجفهمی در روند تحلیل داده جلوگیری شود. در صورتی هم که با دادههای پرت اشتباه سروکار داشته باشیم، باز هم حذف کردن چنین دادهی پرتی ایدهی خوبی است.
- تعریف یک کران بالا یا Topping:
تعیین یک کران بالا نیز میتواند برای مواقعی مفید باشد که در دیتاست خود یکسری مقادیر بسیار بزرگ داشته باشید و متوجه شوید که وقتی همهی آنها از حد معینی عبور میکنند، رفتار یکسانی را از خود نشان میدهند؛ در چنین مواقعی میتوانید این مقادیر را با یک کران بالا تقریب بزنید.
- اختصاص یک مقدار جدید:
اگر اشتباه بودن دادهی پرت کاملا واضح است، می توانید با استفاده از یکی از تکنیکهایی که در بخش قبل مطرح شدند (میانگین یا رگرسیون انتساب) ، یک مقدار جدید به آن اختصاص دهید.
تصمیم اینکه از کدام یک از رویکردهای بالا باید استفاده کرد به نوع و تعداد دادههای پرت بستگی دارد. با این وجود، در بیشتر مواقعی که دادههای پرت بخش کوچکی از کل دیتاست را تشکیل داده باشند، بهترین کار حذف آنهاست.
نکته:
دادههای نویزدار در زمرهی مقادیری قرار میگیرند که یا غلط هستند یا غیر ممکن بنظر میآیند. این دادهها شامل مقادیری عددی(مثلا وقتیکه مسئول ثبت سن دانش آموزان مدرسه هستیم و به اشتباه سن یک دانش آموز را 100 ذخیره کردهایم) و اسمی (به عنوان مثال، جنسیت یک دانشآموز را در اثر یک اشتباه املایی بصورت: "fimale" ذخیره کرده ایم) میشوند. مشابه رویکردهایی که در خصوص دادههای پرت مطرح شد، داده های نویزدار را نیز میتوان با حذف کامل مقادیر یا با اختصاص یک مقدار جدید به آنها، تصحیح کرد.