تغییر مقایس مجدد دادهها
تغییر مقایس مجدد دادهها (Data Rescaling):
اهمیت مقیاسبندی مناسب دادهها در این است که اگر دیتاستی که به مدل داده میشود فیچرهایی با مقیاسهای متفاوت داشته باشد، این عدم همگنی میتواند منجر به این شود که الگوریتمها توانایی خودشان را در استخراج الگو از دیتاست از دست بدهند؛ این قضیه به نوبهی خود منجر به کند شدن سرعت روند آموزش و پدیدار شدن تاثیراتی منفی در عملکرد مدل خواهد شد. در چنین مواقعی، تغییر مقیاس مجدد دادهها تا حدود زیادی به مدل کمک میکند تا سریعتر اجرا شده و تا جای ممکن با هیچ مانعی در راه رسیدن به یک درک درست از دیتاست مواجه نشود.
مدلی که از روی یک دیتاستِ کالیبرهشده آموزش ببیند، وزنههای(سطح اهمیت) یکسانی به همهی پارامترها اختصاص میدهد(با وزنه ها در آینده بیشتر آشنا خواهیم شد). این قضیه نیز به نوبهی خود باعث میشود که الگوریتم موردنظر به همهی فیچرها تعمیم داده شود و نه فقط آنهایی که از مقادیر بالایی برخوردارند.
اگر بخواهیم در این مورد مثالی بزنیم، میتوانید دیتاستی با مقیاسهای متفاوت و فیچرهای متفاوت را در نظر بگیرید که دادههای یکی مربوط به وزن افراد، دیگری مربوط به دمای ایّام و دیگری هم مربوط به تعداد بچهها میباشد. اگرچه همهی این دادهها و مقادیر ثبت شدهی آنها میتواند کاملا منطقی و درست باشد، اما مقیاس آنها با یکدیگر متفاوت خواهد بود. بعنوان نمونه، مقادیر ثبت شده در خصوص وزن افراد میتواند تا عددی بالای 100 کیلوگرم برود اما تعداد بچهها معمولا بیشتر از 10 نفر نخواهد شد.
دو تا از محبوبترین روشها درخصوص مقیاسبندی مجدّد دادهها عبارتند از: نُرمالیزاسیون دادهها(data normalization) و استانداردسازی دادهها(data standardization). در این زمینه هیچ قانونی در مورد انتخاب بهترین روش برای تبدیل دادهها وجود ندارد، زیرا هر دیتاستی در مقایسه با دیگری رفتار متفاوتتری دارد. مناسبترین رویکرد این است که دادهها را با استفاده از دو یا سه روش، مجددا مقیاسبندی کرده و با تستکردن الگوریتمها را در هر روش و با توجه به بازخوردی که میگیریم، بهترین روش را انتخاب کنیم.
نکتهای که باید به آن توجه کنید این است که هر کدام از این روشها باید بهصورت جداگانه استفاده شوند تا به هنگام تستکردن هر روش، تغیر مقیاس مجدد دادهها بصورت مستقل صورتگیرد. نهایتا هم دیتاست حاصل از اعمال مقیاسبندی های جدید، باید روی مدل موردنظر آزمایش شود و مناسبترین مورد انتخاب شود.
نُرمالیزاسیون:
نُرمالیزاسیون دادهها در حوزهی یادگیری ماشین شامل تغییر مقیاس مجدد مقادیر به نحوی است که مقادیر جدید در محدودهی بین 0 و 1 قرار بگیرند و حداکثر طول آنها یک باشد.
معادلهی زیر به شما اجازه میدهد تا مقادیر یک فیچر را نُرمالایز کنید:
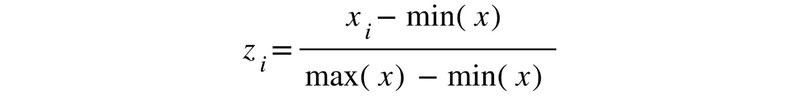
در اینجا، z با i اُمین مقدار نرمالایز شده مطابقت دارد. x هم نمایانگر همهی مقادیر است.
استاندارد سازی:
این تکنیک، دادهها را به فرم یک توزیع گاوسی با مقدار میانگینی برابر صفر و انحراف معیاری برابر 1 تبدیل میکند.
یک روش ساده بمنظور استاندارد سازی یک فیچر، در معادلهی زیر نشان داده شده است:
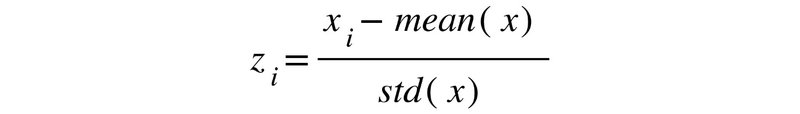
در اینجا، z با i اُمین مقدار استانداردسازی شده مطابقت دارد. x هم نمایانگر همهی مقادیر است.