Supervised Learning
یادگیری تحت نظارت (Supervised Learning ) :
یادگیری تحتنظارت، هنرِ درک ارتباط بین یک مجموعهی مشخص از فیچرها و یک مقدارِ هدف(target value) میباشد که از آن با عنوان برچسب(label) یا کلاس(class) نیز یاد میشود. به عنوان مثال همانطوریکه در جدول زیر نشان داده شده است، میتوان از یادگیری تحتنظارت بمنظور مدلسازیِ رابطهی بین اطلاعات دموگرافیک افراد و توانایی آنها در پرداخت وام استفادهکرد:
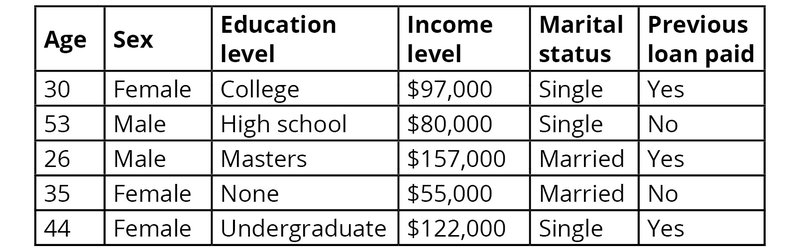
متعاقباً، مدلهایی که برای پیشبینی این روابط آموزش داده شدهاند را میتوان در خصوص پیشبینی برچسبهایی برای دادههای جدید نیز بکار برد. همانطوریکه در مثال فوق میبینید؛ بانکی که بدنبال ایجاد چنین مدلی باشد می تواند با وارد کردن دادههای افرادی که متقاضیان وام هستند، تعیینکند که آیا احتمال دارد وام را بازپرداخت کنند یا خیر؟!
وظایف قابل اجرا توسط این تیپ از مدلها را میتوان به دو قسم کرد: طبقه بندی(Classification) و رگرسیون(Regression)؛ در ادامه به تشریح این دو مورد میپردازیم.
1- امورات مربوط به Classification، در خصوص ساخت مدلهایی از روی دادههایی با کتِگوریهای گسسته مطرح هستند که طبیعتا بعنوان برچسب (label) مورداستفاده قرار میگیرند؛ به عنوان نمونه، پیشبینی اینکه آیا فردی وام خود را بازخواهد گرداند یا خیر، در این قسم از امورات قرارمیگیرد.
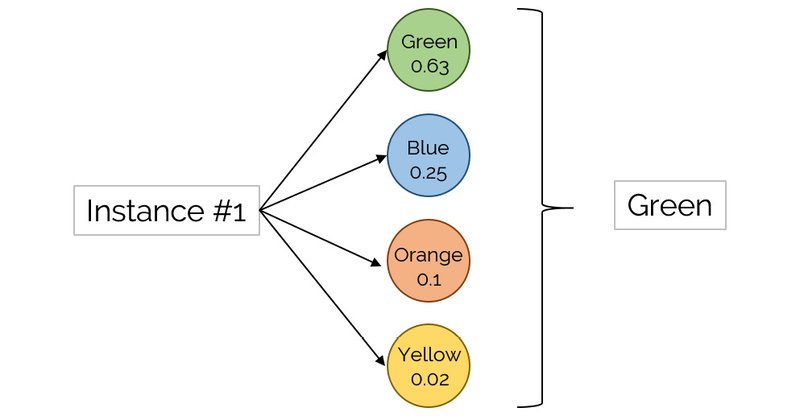
خروجی اکثر امورات این تیپی، پیشبینیِ نسبت احتمال تعلق یک نمونه به تک تک برچسبهای خروجی میباشد. در نمودار زیر، برچسب موردانتظار ما همانی میباشد که بالاترین احتمال را دارد:
برخی از رایجترین الگوریتمهای طبقهبندی به شرح زیر میباشند:
- درختهای تصمیم گیری (Decision trees): این الگوریتم از یک معماری درختمانند پیروی میکند که فرآیند تصمیم گیری را با استفاده از یکسری تصمیمات و با در نظرگرفتن یک متغیر در انِواحد، شبیه سازی میکند.
- طبقهبندی کنندهی Naïve Bayes: این الگوریتم متکّی به گروهی از معادلات احتمالسنجی بر اساس تئوریِ Bayes میباشد که فیچرها را بطور مستقل و بدون نیاز به یکدیگر بررسی میکند.
- شبکه های عصبی مصنوعی(Artificial neural networks) یا ANN: شبکههای ANN، تقلیدی از ساختار و عملکرد یک شبکهی عصبی بیولوژیکی هستند که بمنظور پیادهسازی الگوهای مربوط به مسائل تشخیص و شناسائی مورد استفاده قرار میگیرند. یک ANN مجموعه ای از نورونهای به هم پیوسته و با معماری مجموعهای میباشد که عملیات انتقال اطلاعات به یکدیگر را تا زمان حصول نتیجه، ادامه میدهند.
2- امورات مربوط به Regression در خصوص دادههایی مطرح هستند که برچسبهای آنها یکسری کمیتهای پیوسته میباشند؛ به عنوان نمونه، پیشبینی قیمت خانهها را میتوان در زمرهی این قسم از امورات قرارداد. این بدین معناست که مقادیر در قالب یک کمیت عرضه میشوند و نه بصورت یکسری خروجیهای محتمل. برچسبها میتوانند از نوع اعشاری یا صحیح باشند.
الگوریتمهای رگرسیون بطور خلاصه به شرح زیر میباشند:
- رگرسیون خطی(Linear Regression): محبوبترین الگوریتم در خصوص مسائل رگرسیونی میباشد که ارتباط بین یک فیچر(y) را که تابعی از یک فیچر دیگر(x) میباشد را بصورت خطی نمایش میدهد. این الگوریتم اغلب بخاطر سادگیاش نادیده گرفته میشود، و این در حالی است که در خصوص مسائل دادهمحور ساده بخوبی عمل میکند!
- سایر الگوریتمهای رگرسیونیِ پیچیدهتر شامل: regression tree و support vector regression و همچنین ANNها میشوند.(ANNها در مسائل رگرسیونی هم کاربرد دارند.)