جداول داده
جداول داده
اکثر جداولی که مسائل یادگیری ماشین از آنها تغذیه میکنند، دو بعدی بوده و شامل سطرها و ستونهایی میباشند. در کل؛ هر ردیف نشان دهندهی یک نمونهی ثبت شده، و هر ستون نمایانگر مشخصهای از نمونهی موردنظر میباشد.
جدول زیر، بخشی از یک دیتاسِت ساده میباشد که با هدف تفکیک سه گونه از گل زنبق، بر اساس مشخصههایشان تشکیل شده است. از این رو؛ در جدول زیر هر ردیف نشان دهندهی داده های ضبط شده برای یک گل، و هر ستون نمایانگر مقدار مشخصهی مرتبط با هر گل میباشد: (این بخش از جدول فقط منحصر به گونهی setosa میباشد.)
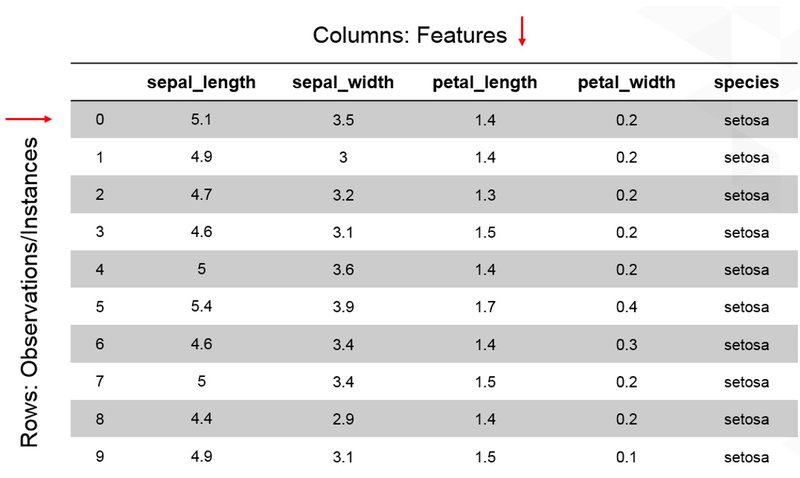
با توجه به توضیحات فوق و با مرور ردیف اول جدول، می توان چنین استنتاج کرد:
یک نمونه گل زنبق از گونهی setosa مشاهده شده، و داده های مربوط به آن از قبیل طول کاسبرگ(5.1)، عرض کاسبرگ(3.5)، طول گلبرگ(1.4) و عرض گلبرگ(0.2) ثبت شدهاند.
توجّه:
اگر یک مدل از روی تصاویر تغذیه کند یا به عبارتی دادههای دریافتی آن در قالب تصاویر باشند، جداول سه بعدی خواهند شد؛ در این مواقع، ردیفها و ستونها نمایانگر ابعاد تصویر در واحد پیکسل بوده، و عمق یا طبقهی جدول نمایانگر طیف رنگی خواهد بود.
به دادههای جدولبندی شده، دادههای ساختاریافته یا به اصطلاح: "structured data" نیز میگویند. از طرفی، دادههای بدونساختار نیز به هر چیزی اشاره دارند که نمی تواند در یک دیتابیس جدولمانند (یعنی در قالب ردیفها و ستونها) ذخیره شود. این تیپ دادهها شامل تصویر، صدا، ویدئو و متن (مانند ایمیل ها) می شوند. برای اینکه بتوان دادههای بدونساختار را به خورد یک الگوریتم یادگیری ماشین داد، در اولین قدم باید آنها را به فرمتی تبدیل کرد که الگوریتم موردنظر بتواند آنرا درک کند (مانند جدول دادهها). به عنوان مثال؛ تصاویر به ماتریسهایی از پیکسلها، و متون به مقادیر عددی کدگذاری شده تبدیل می شوند.