Unsupervised Learning
یادگیری بدوننظارت (Unsupervised Learning):
یادگیری بدوننظارت عبارتست از تجهیزکردن مدل با دادههایی که با برچسبهای خروجی ارتباطی ندارند، که معمولا به آنها دادههای بیبرچسب یا به اصطلاح: " Unlabeled data " نیز گفته میشود. این بدان معناست که الگوریتم های این حوزه، سعی در درک و الگویابی داده دارند. به عنوان مثال همانطوریکه در نمودار زیر نشان داده شده است، می توان از یادگیری بدوننظارت برای درک مشخصات افراد متعلق به یک محله استفاده کرد.
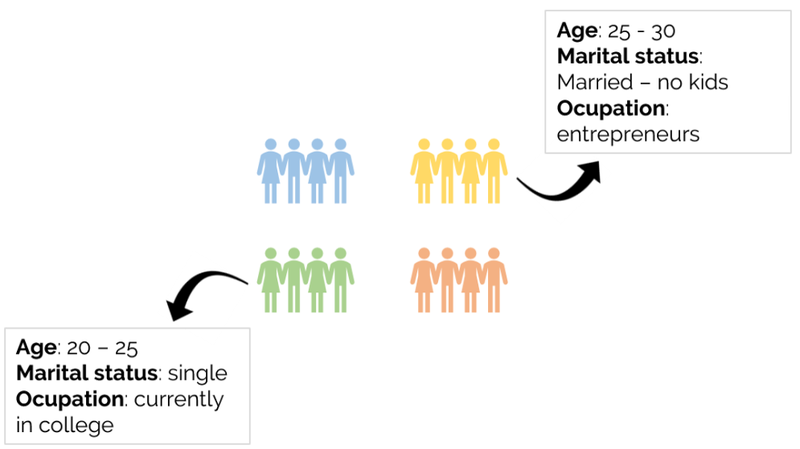
لازم به ذکر هست که بههنگام اعمال یک پیشبینی کننده یا predictor به الگوریتمهای این حوزه، هیچ برچسبِ هدفی به عنوان خروجی تعیین نمیشود و پیشبینیِ حاصل(که فقط برای برخی مدلها در دسترس است) نیز عبارت خواهد بود از قرار دادن نمونهای جدید در یکی از زیرگروههای ایجاد شده.
مسائل مربوط به حوزهی یادگیری بدوننظارت به چند قسم میباشند که محبوبترین آنها خوشهبندی یا به اصطلاح: " Clustering " میباشد.
مسائل مربوط به خوشهبندی یا Clustering، شامل ایجاد گروههایی از دادهها (خوشهها) میباشد که مطیع این شرط هستند: نمونههای یک گروه باید بهطور شهودی با نمونههای حاضر در درون گروههای دیگر متفاوت باشند. خروجی هر الگوریتم خوشهبندی، یک برچسب میباشد که نمونهی موردنظر را به خوشهی مربوط به برچسب اختصاص میدهد.
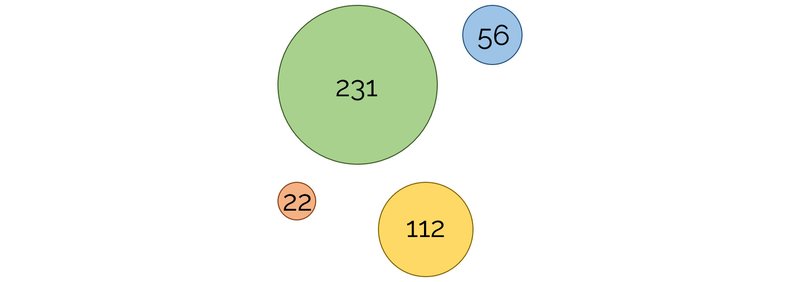
تصویر فوق، گروهی از خوشهها را نشان میدهد که هر کدام اندازههای متفاوتی دارند. این اندازهها براساس تعداد نمونههایی که به هر خوشه تعلق دارند، تعیین شدهاند. حتی با وجود اینکه خوشهها قرارنیست تعدادِ یکسانی نمونه داشته باشند، میتوان یک مقدار حداقل برای تعداد نمونههای هر خوشه تنظیم کرد تا از برازش بیش از حد دادهها یا به اصطلاح: " overfitting " در خصوص وجود خوشههای کوچکی که در دادههای بسیار دقیق و خاص به آنها احساس نیاز میشود، جلوگیری کرد.
برخی از محبوب ترین الگوریتمهای خوشهبندی به شرح زیر است:
- الگوریتم k-means: این الگوریتم بر جداسازی نمونهها به n خوشه با واریانس مساوی و با به حداقل رساندن مجموع مجذور فاصلههای بین دو نقطه تمرکز دارد.
- الگوریتم Mean-shift clustering: در این الگوریتم، خوشهها با استفاده از مراکز ثقل ایجاد میشوند؛ بدین صورت که هر نمونه به عنوان کاندیدی برای مرکز ثقل بودن مطرح میشود تا صلاحیت آن به عنوان یک میانگین برای نقاط حاضر در آن خوشه بررسی شود.
- الگوریتم Density-Based Spatial Clustering of Applications with Noise یا به اختصار DBSCAN: طرز کار این الگوریتم بدین صورت است که خوشههایی با سایز بزرگ را بصورت مناطقی با تراکم نقاط بالا نشان میدهد که توسط مناطقی با تراکم کم از هم جدا شدهاند.