خواندن Data
خواندن Data
در دو قسمت قبل در مورد دانلود دیتا و محل ذخیره سازی آن صحبت کردیم. مهم ترین مسئله در کارکردن با dataset به شکل فایل پسوند یا extension فایل است. dataset ما از نوع فایل csv است اما پسوند های مختلف دیگری نیز وجود دارند. csv مخفف Comma-Separated Values است. در این فایل ها اطلاعات با , و ; از یکدیگر تفکیک شده اند. این فایل ها بسیار پرطرفدار هستند و pandas به خوبی آن ها را مدیریت میکند. لیست تمام منابع ورودی قابل پشتیبانی pandas را در تصویر زیر میبینید.
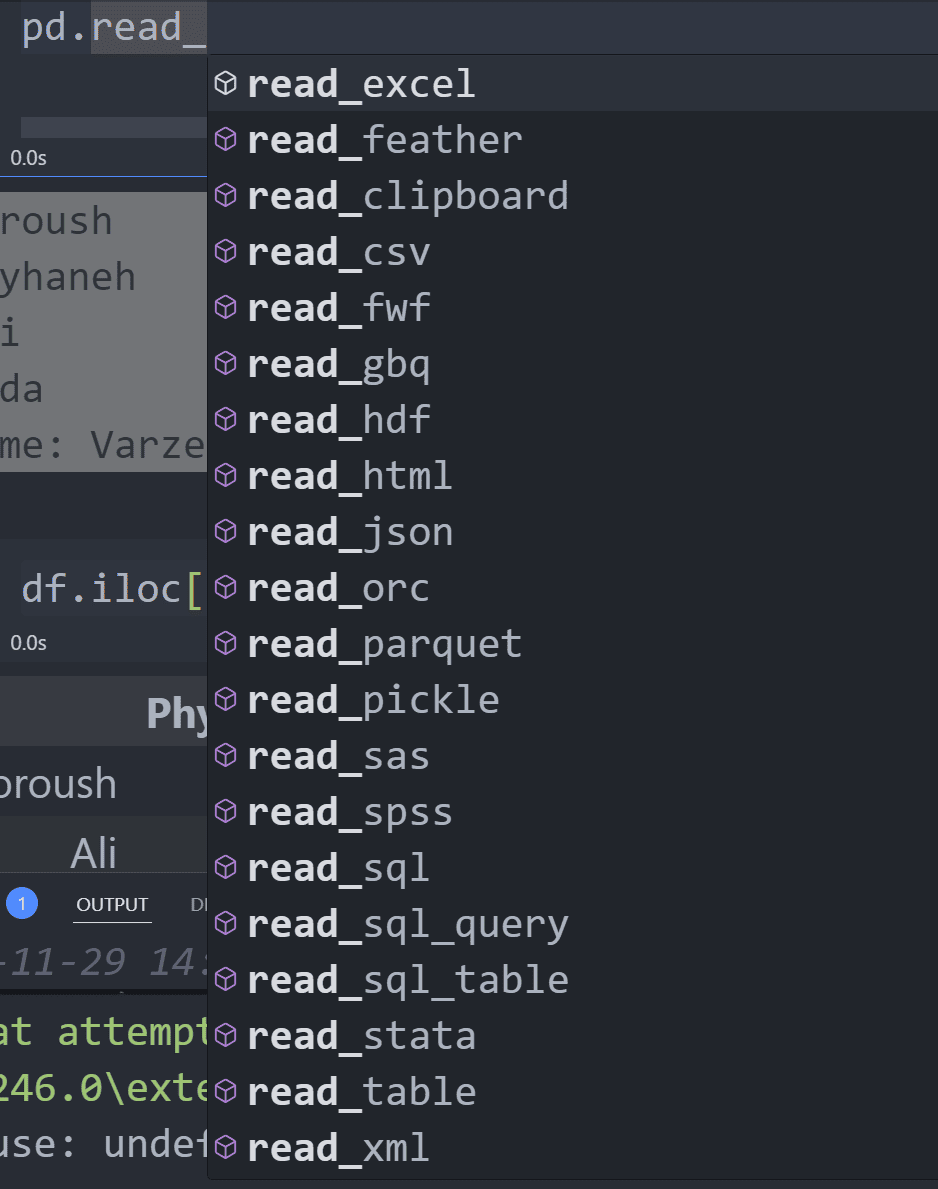
اگر فایل ها مرتب و تمیز باشند بدون پیغام خطا و تنها با دادن آدرس فایل میتوانید با استفاده از دستور مرتبط فایل را بخوانید، اگر فایل ها مرتب و تمیز نباشند نیز 2 راه پیش رو دارید، یا تنظیمات دستور مربوط به خواندن را دستکاری کنید و یا فایل را دستکاری و تمیز کنید. خطاهای مختلفی در این مورد پیش می آید که هرکدام نیاز به بررسی و سرچ کردن دارند.
از طرف دیگر برای کار با دیتا به DataFrame احتیاج داریم و pandas پس از خواندن فایل ها خروجی را به صورت DataFrame میدهد و باید آن را باز گردانیم.
نکته:
زمانی که تنها یک DataFrame در پروژه وجود دارد از نام متغیر df استفاده میکنیم. البته میتوانید اسامی خواناتر و بهتری را بکار بگیرید و اگر چند DataFrame در پروژه موجود باشد بهتر است هرکدام نام مشخص و منحصر بفرد خود را داشته باشد.
مسئله ی دیگری که متاسفانه در این دوره به آن پرداخته نمی شود فایل های parquet هستند. این فایل ها بسیار سبک و دسترسی پذیر هستند. حجم کم این فایلها و دسترسی سریع به محتوای آنها، فایل های parquet را برای کار با دیتای بزرگ و سنگین و انتقال اطلاعات به صورت فایل کاملا مناسب میکنند.
لطفا اگر قصد ورود به حوزه های مرتبط با دیتا را دارید، در مورد این فایل ها مطالعه کنید و ساخت و استفاده از آنها را یاد بگیرید. این کار بسیار ساده است!