آشنایی با deep learning
آشنایی با deep learning
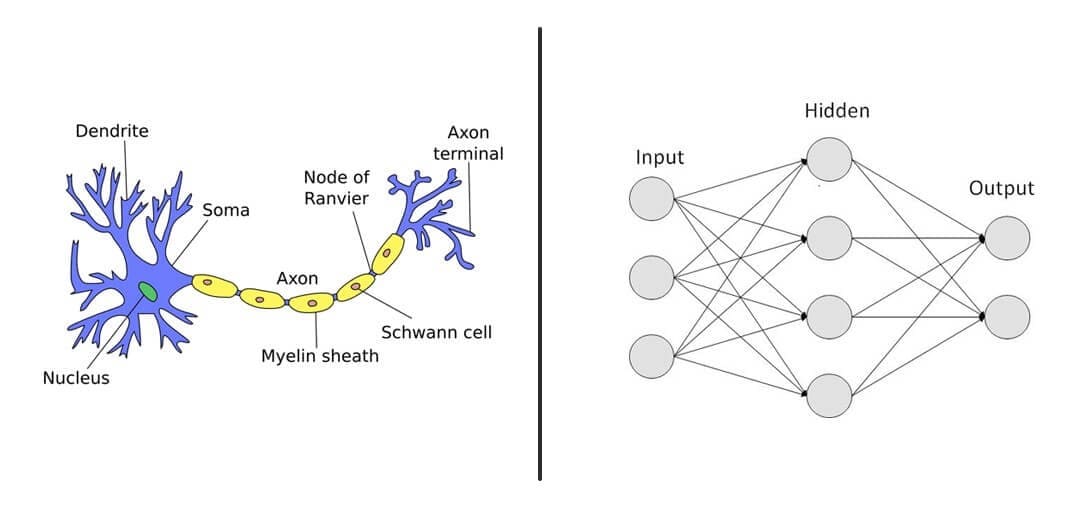
گفتیم که شبکه های deep learning الگویی از نورون های مغز انسان هستند. در دنیای deep learning به هر نورون یک node گفته میشود. در تصویر زیر یک سلول عصبی(عملکرد مشابه چند نورون دارند) و یک شبکه با 9 عدد node را میبینید. هر node یک واحد محاسباتی است. هر node میتواند به تنهایی مهم باشد اما وقتی عملکرد بهتری میبینیم که node های زیادی در کنار یکدیگر کار کنند.
اگر از 2 فصل قبل دیتاست Boston Housing را به خاطر داشته باشید، هر ستون یک node از الگوریتم linear regression ما بود، این node در یک مقدار ثابت که وزن (weight) نام داشت ضرب میشد و خروجی این ضرب ها با یکدیگر جمع میشدند:
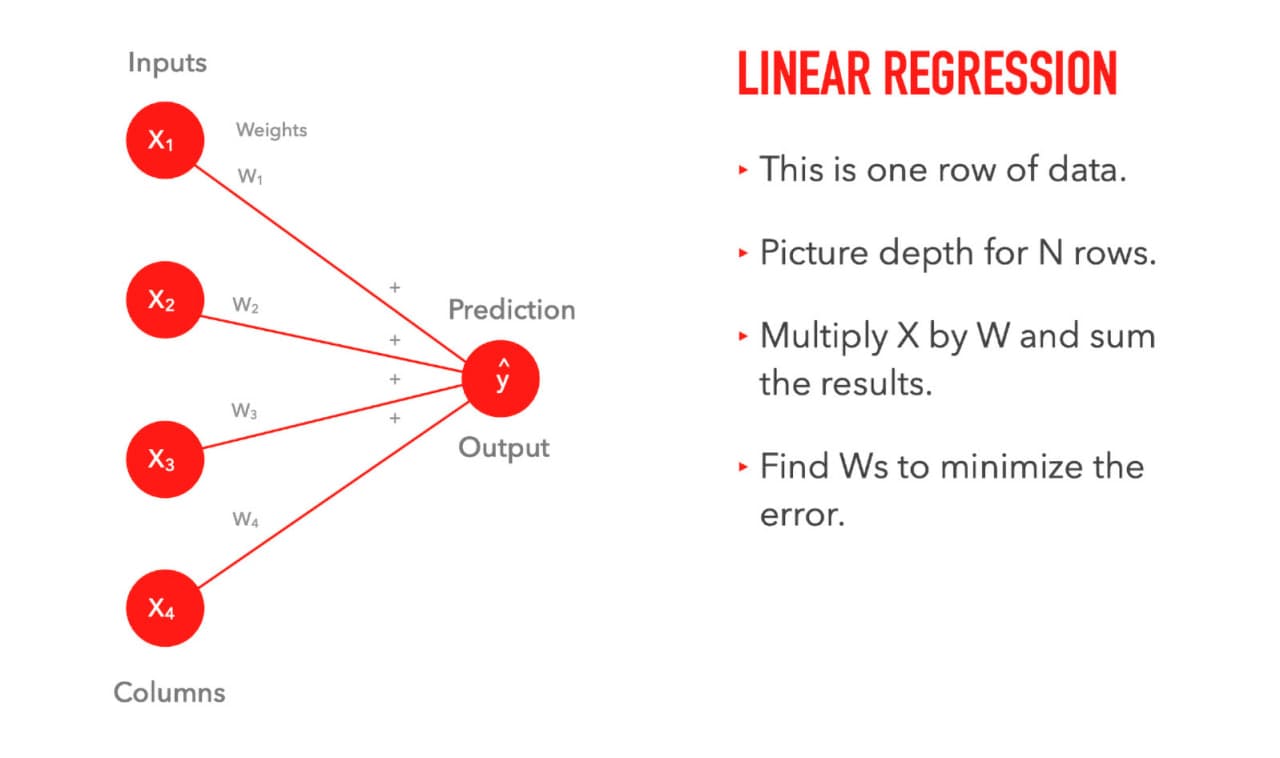
به این پردازش به خاطر ساده بودن و فرمول خطی Y = MX یک پردازش خطی یا linear میگوییم. در حالت linear فقط ضرب و جمع وجود دارند.
بین روش linear و روش deep learning (غیر خطی یا non-linear) 2 تفاوت وجود دارد!
activation function
اولین تفاوت وجود تابع فعال سازی یا activation function است. بعد از انجام عملیات جمع و ضرب نتیجه ی محاسبات node ها با ورود به یک activation function فعال می شود. activation function یک تابع nonlinear است. ایده ی activation function این است که بخشی از نورون ها یا node ها فعال شوند و خروجی همه تاثیر گذار نباشد. مثلا در مغز فکر کنید میخواهید آب بخورید و آب بخورید! اگر نورون های اشتباهی در مغز شما فعال شوند ممکن است به جای آب خوردن موبایل خود را بردارید یا فلفل بخورید!
اگر از فصل قبل به خاطر داشته باشید زمان استفاده از logistic regression از تابع Sigmoid نیز صحبت کردیم که یک تابع غیر خطی است که اجازه ی classify کردن داده ها در دو گروه را به ما میدهد. Sigmoid یک تابع غیر خطی است:
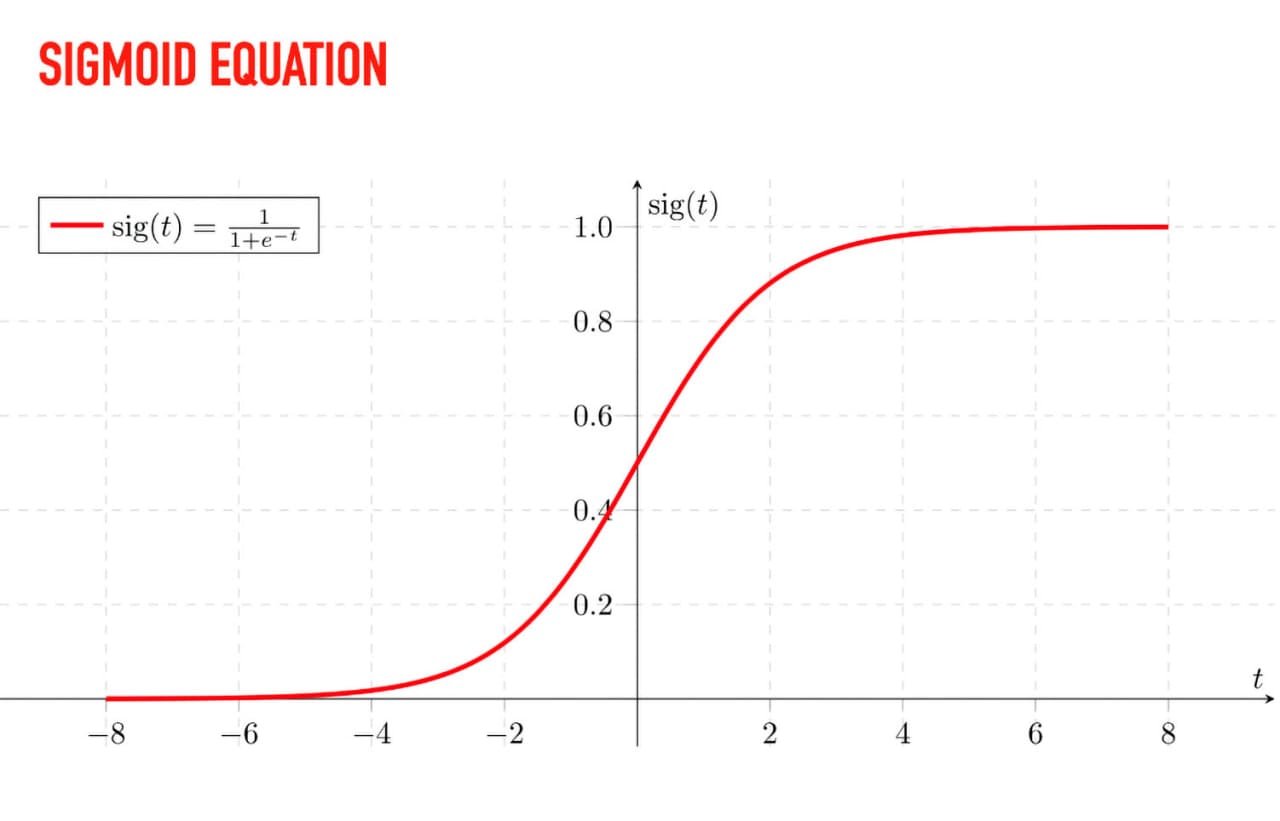
پس از انجام محاسبات node ها نتیجه ی نهایی به یک تابع فعال سازی مانند Sigmoid داده می شود و نتیجه یک خروجی nonlinear خواهد بود. در deep learning بر خلاف logistic regression تابع فعال سازی روی هر node بین لایه ی اول (first) و لایه ی آخر (last) اعمال می شود. تمام شبکه های deep learning به شکل nonlinear هستند و این غیر خطی بودن به ما اجازه ی یافتن الگوهای پیچیده تر و تشخیص های پیچیده تر را میدهد. activation function های دیگری نیز وجود دارند، مانند تانژانت هیپربولیک (tanh) یا rectified linear unit (رِلو یا relu) که میتوانیم از آنها به عنوان جایگزین Sigmoid استفاده کنیم.
node های زیاد
دومین تفاوت در این است که میتوانیم هرچقدر میخواهیم node داشته باشیم.
هر چقدر میخواهیم!
هر چقدر میخواهییییم!
به تصویر بعدی توجه کنید:
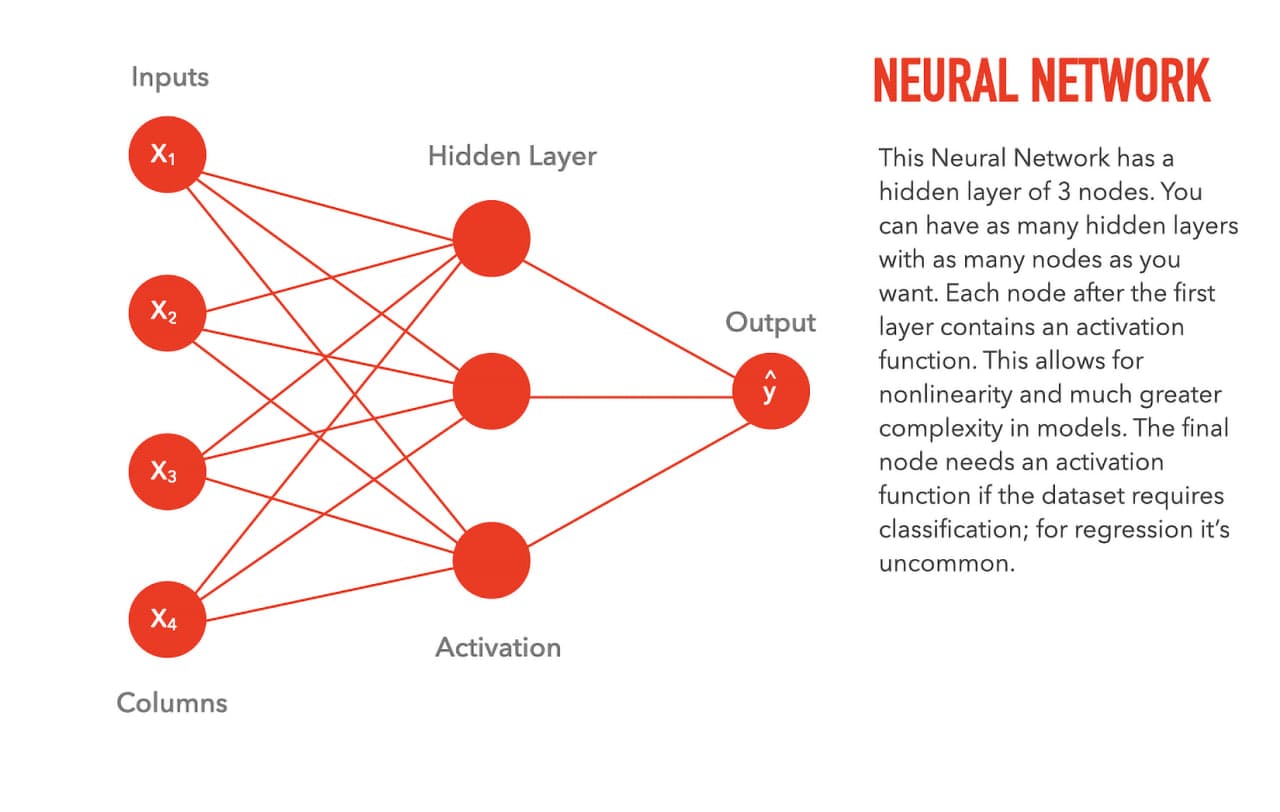
تعداد column های ورودی برابر با تعداد node های لایه ی اول است، هر خط نشانگر یک وزن و تعداد node های لایه ی آخر (در اینجا 1 node ) برابر با تعداد خروجی مورد انتظار. هر node بین لایه ی اول و آخر نیز یک تابع غیر خطی (activation function) است. بین لایه ی اول و آخر میتوانیم هرچقدر میخواهیم لایه و گره (layer & node) داشته باشیم. به تعداد خط های وزن ها تعداد پارامتر نیز گفته میشود. تصویر بالا یک شبکه ی 15 پارامتری را نمایش میدهد. اگر تمام node های تمام لایه ها به تمام node های لایه های بعدی و قبلی خود متصل باشند، اصطلاحا یک شبکه ی densely connected یا fully connected داریم. با افزایش تعداد پارامترها حجم محاسبات افزایش میابد.
بیایید یک حالت پیچیده تر را ببینیم:
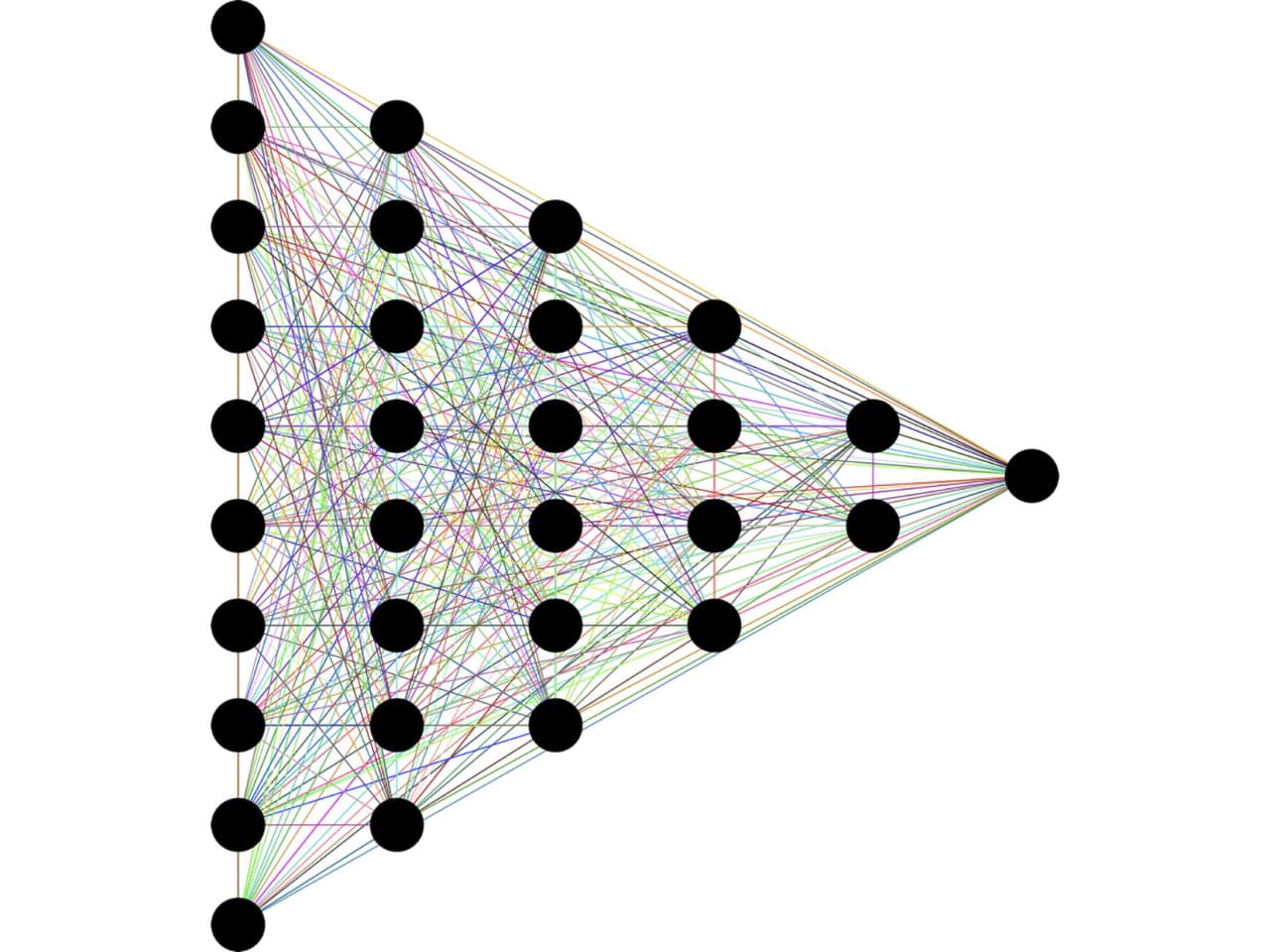
پارامترهای شبکه ی بالا بسیار بیشتر از شبکه قبل است. البته هردو در دنیای واقعی deep learning بسیار کوچک حساب می شوند.