معرفی فصل
در این فصل مبانی Docker و containerization را می آموزید و درک می کنید که چرا باید از ساختارهای سنتی و multi-tier اپلیکیشن ها به زیرساخت های سریع و قابل اعتماد کانتینری مهاجرت کرد. در پایان این فصل شما یک درک عمیق وکاربردی از مزایای containerized applications خواهید داشت و می توانید کانتیرهای ساده را اجرا کنید.
این فصل شامل تمامی مفاهیم پایه ای مورد نیاز در فصل های بعد است پس حتی اگر عجله دارید، لطفا برای این فصل تا حد ممکن زمان بگذارید.
معرفی
در سالهای اخیر به لطف پیشرفت تکنولوژی از بازه های 1 ساله ی تولید نرم افزار، در تمام صنایع نرم افزاری به بازه های کوتاه تر هفتگی، روزانه و حتی لحظه ای توسعه ی نرم افزار رسیدیم. ترند( trend)های توسعه ی تکنولوژی (مثلا agile development و continuous integration pipelines )، برنامه نویسان بیشتر از همیشه نیازمند یک زیرساخت سریع و قابل اعتماد هستند تا بتوانند پاسخگوی نیاز صنعت، بازار و مشتریان باشند.
علت مهاجرت شرکت ها به زیرساخت های ابری نیز دقیقا همین موضوع است.
زیرساخت های ابری انواع مختلفی دارند اما تمام آنها 3 خدمت هاست مجازی( hosted virtualization )، شبکه( network ) و فضای ذخیره سازی( storage ) را ارائه می دهند. ارائه دهندگان این زیرساخت ها سرویس های خود را در اختیار شرکت ها و افراد مختلف قرار می دهند، در گذشته اما برای ایجاد یک وب سرویس به سرورهای گران قیمت اختصاصی و مالکیت(دائمی یا اجاره) فضای سرور در دیتاسنترها یا فضای شخصی نیاز بود.
امروزه این اتفاق تنها با چند کلیک و تقریبا در لحظه به صورت خودکار رخ می دهد.
انتقال زیر ساخت ها از حالت سنتی به ابری مشکلات بسیار زیادی را حل می کند اما در کنار این مسئله مشکلات اضافه تری را نیز ایجاد می کند که عموم آنها مربوط به مدیریت هزینه و مدیریت تعداد بسیار زیادی از سرویس ها هستند. چطور در تمام طول سال باید این سیستم های پیچیده را سر پا نگه داشت؟
ماشین های مجازی( virtual machines ) -که از این به بعد با نام VM از آنها یاد می کنیم- انقلابی در صنعت زیرساخت ها بودند. VM ها با بکارگیری hypervisor ها به ما اجازه ی ایجاد سرورهای کوچک تر روی یک سخت افزار بزرگتر را می دادند. عیب اصلی VM ها این بود که استفاده از آن ها نیازمند بکارگیری بخش زیادی از منابع بود. VM ها از لحاظ ظاهری، رفتاری، عملکرد و مشابهت کاملا مانند سیستم عامل های روی سخت افزار( bare metal hardware ) عمل می کردند علت این مسئله این بود که hypervisor هایی مثل Zen ، KVM و VMWare نیاز به مدیریت منابع برای boot و مدیریت تصاویر کامل سیستم عامل داشتند؛ ضمنا انتقال اطلاعات برای تغییر زیرساخت ابری بر پایه ی VM ها نیازمند انتقال چند ده(یا چند صد) گیگابایت داده از مبدا به مقصد بود.
این وضعیت برای هیچ کس قابل تحمل نبود! برای افزایش اتوماسیون فرآیندها، بهبود مصرف منابع و دریافت سهم بیشتری از بازار با هزینه ی کمتر، شرکت ها به سراغ تکنولوژی های جدیدتر مثل containerization و بکار گیری معماری های میکروسرویسی رفتند. Containerها تکنولوژی های جدیدتر ( و در آن زمان نا پخته تر) بودند که اجازه ی اجرای سرویس های نرم افزاری به صورت ایزوله را با استفاده از یک kernel بر روی سیستم عامل اصلی ارائه میدادند که هر محیط در سطح پردازشی( process-level ) کاملا ایزوله بود.
این تکنولوژی جدید به جای اجرای یک kernel سیستم عامل کامل برای هر سرویس، یکی kernel اشتراکی را بر روی سیستم عامل میزبان( host ) ارائه می داد که میتوانست تعداد بسیار زیادی از برنامه ها را به صورت ایزوله اجرا کند. Containerها بر پایه دو ویژگی Linux kernel به نام های control groups ( cgroups ) و namespace isolation بنا شده بودند. با استفاده از Containerها کاربران می توانستند روی تنها یک VM یا یک کامپیوتر فیزیکی صدها Container را اجرا کنند که هرکدام یک instance مجزا از یکی از سرویس ها باشد.
به صورت عمومی VM ها هنوز هم کاربرد دارند و زمانی که بخواهیم تنها یک سرویس (مثلا هاست ایمیل) یا تعداد بسیاری کمی از سرویس ها را روی یک سرور داشته باشیم، از VM ها استفاده می کنیم. با این کار شاید از منابع ارزشمند CPU و RAM به درستی استفاده نکنیم اما کار خود را کمی ساده تر کرده ایم. حالا فرض کنید بعد از انجام این کار نیاز به گسترش تعداد سرویس های خود داریم؛ با اینکه در ابتدا استفاده از VM ها منطقی به نظر می رسید، با افزایش تعداد سرویس ها میزان هدر رفت منابع ارزشمند CPU و RAM به شکل خطی افزایش پیدا می کند.
علت استقبال از رویکرد containerized microservices هم دقیقا همین مسئله بود! کانتینر به نوع اپلیکیشنی که در داخل خود اجرا می کند اهمیت نمی دهد و صرفا با تنظیمات تعریف شده و بر پایه ی kernel آن را اجرا می کند. به همین خاطر با صرف نظر از مصرف اضافه ی منابع، kernel را به کار می گیرد تا برنامه را اجرا کند. مهم نیست که برنامه ی داخل کانتینر یک Go web API یا یک Python script ساده باشد، از آنجایی که کانتینر یک فرمت استاندارد است! محیط اجرای آن( container runtime ) تنظیمات مورد نیازش را دانلود و دریافت می کند و برنامه را اجرا می کند. یکی از موارد مهمی هم که در طول دوره به آرامی یاد میگیرید، عملکرد دقیق container runtime است.
داکر( Docker ) یک container runtime است که در سال 2013 توسعه داده شد و هدف از توسعه ی آن بهره گیری بیشتر از ویژگی process isolation در Linux kernel بود. چیزی که داکر را از دیگر پیاده سازی های container runtime جدا می کرد قابلیت های جدید build و push کانتینرها در ریپازیتوری های کانتینری بود. این خلاقیت منجر به ایجاد مفهوم container immutability (یعنی بروزرسانی کانتینر فقط با build و push انجام می شود و مانند کنترل نسخه تنها با تغییرات سر و کار خواهیم داشت.) نیز در صنعت نرم افزار شد.
به شکل زیر دقت کنید:
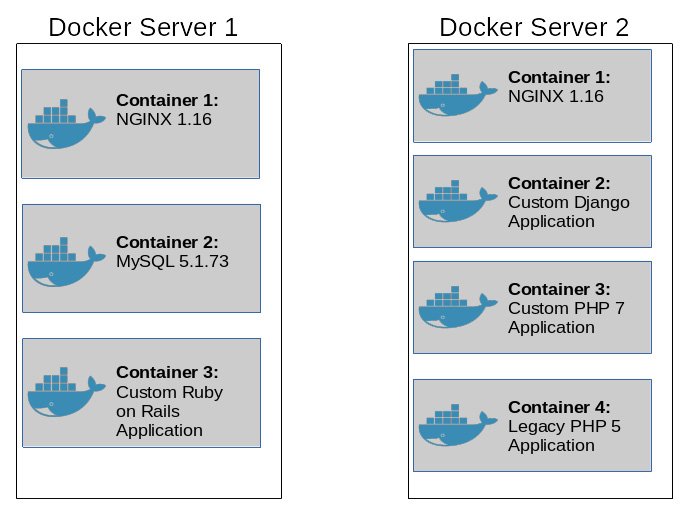
در این شکل ما دسته های برنامه های کانتینری شده( containerized applications ) را داریم که روی 2 سرور داکر دیپلوی شده اند. روی دو سرور ما مجموعا 7 containerized application وجود دارد و هر کانتینر دستورات، کتابخانه ها و وابستگی های بسته( self-contained dependencies ) های خود را دارد. زمانی که داکر یک کانتینر را اجرا می کند، خود کانتینر تمام چیزهایی که برای عملکرد درست نیاز دارد را در خود میزبانی می کند. امروزه حتی می توانیم چند نسخه ی متفاوت از یک برنامه را در یک سرور داکر اجرا کنیم چرا که هر کانتینر در فضای کرنلی ( kernel space ) خودش وجود دارد.